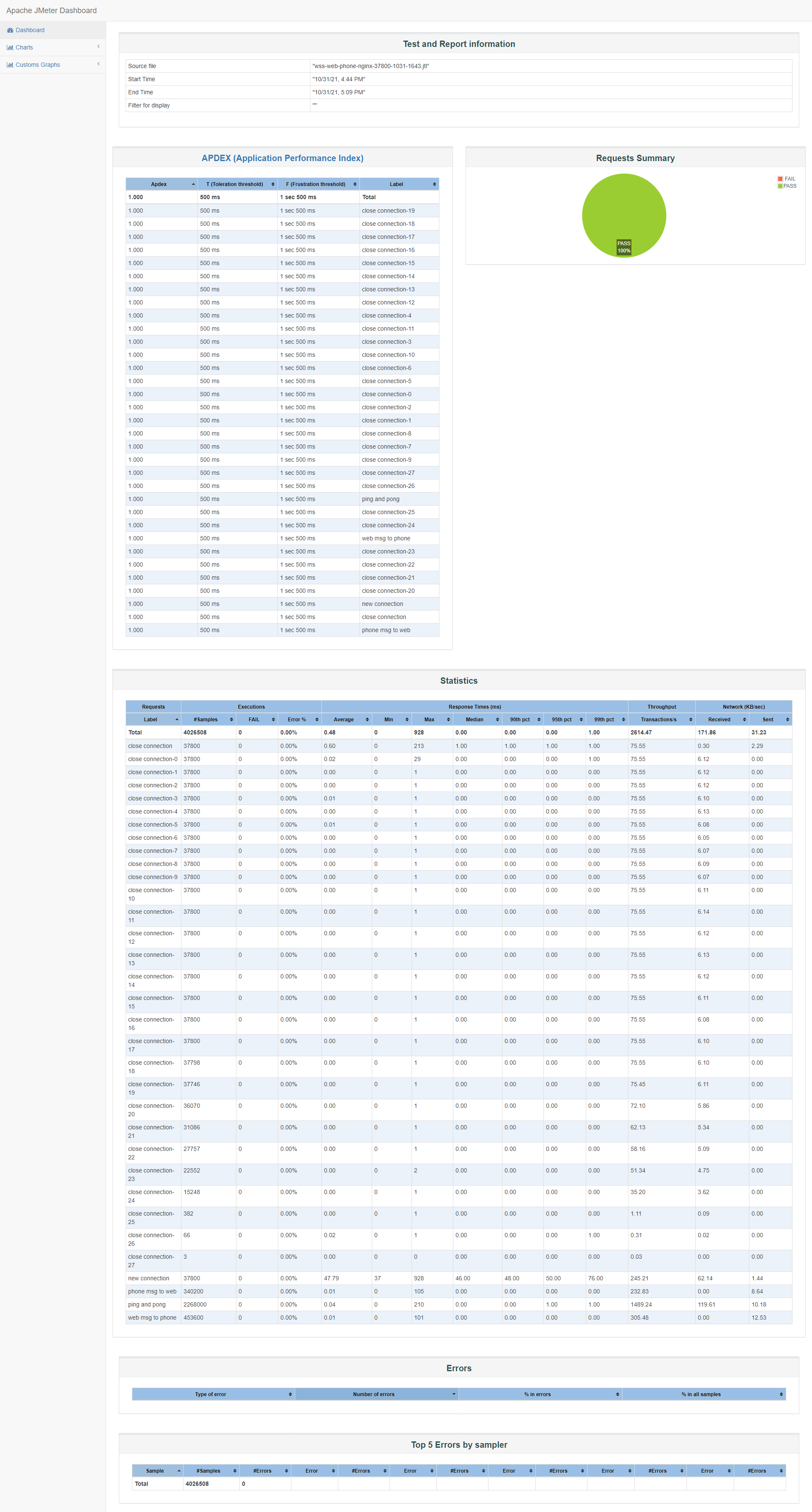
websocket+ssl压测报告
目录
本次是比对两种wss提供方式。
- 方式一、被测服务wssrv自身监听9088端口,提供wss协议给客户端直连
- 方式二、通过被测服务wssrv监听8088端口,提供ws协议连接服务,nginx对外监听443端口接收wss协议连接,再转发由后置的wssrv服务处理(ws协议8088端口)
我们希望对外提供业界标准的协议端口号。
说明
名词解释
-
web端
web端理解为控制端,比如parent端
-
phone端
phone端理解为被控端,比如kid端
-
wss直连
被测服务直接监听9088端口,客户端直接连接9088端口使用wss协议连接服务。
-
nginx+wss
被测服务监听8088端口,nginx对外提供443端口接收wss协议连接,再转发给被测服务监听的8088端口处理。
-
响应时间
客户端连接超时时间为10s,读取响应超时时间为6s(目前只有连接和心跳时才有考虑读取响应超时)
-
场景
根据服务的业务,考虑几个场景:并发连接、并发连接且保活、阶梯连接且保活、模拟web端远程控制phone端、服务端并发主动断开连接。
每个场景有相应的脚本配置逻辑与用户线程数设计,详见每个场景。
-
图表报告
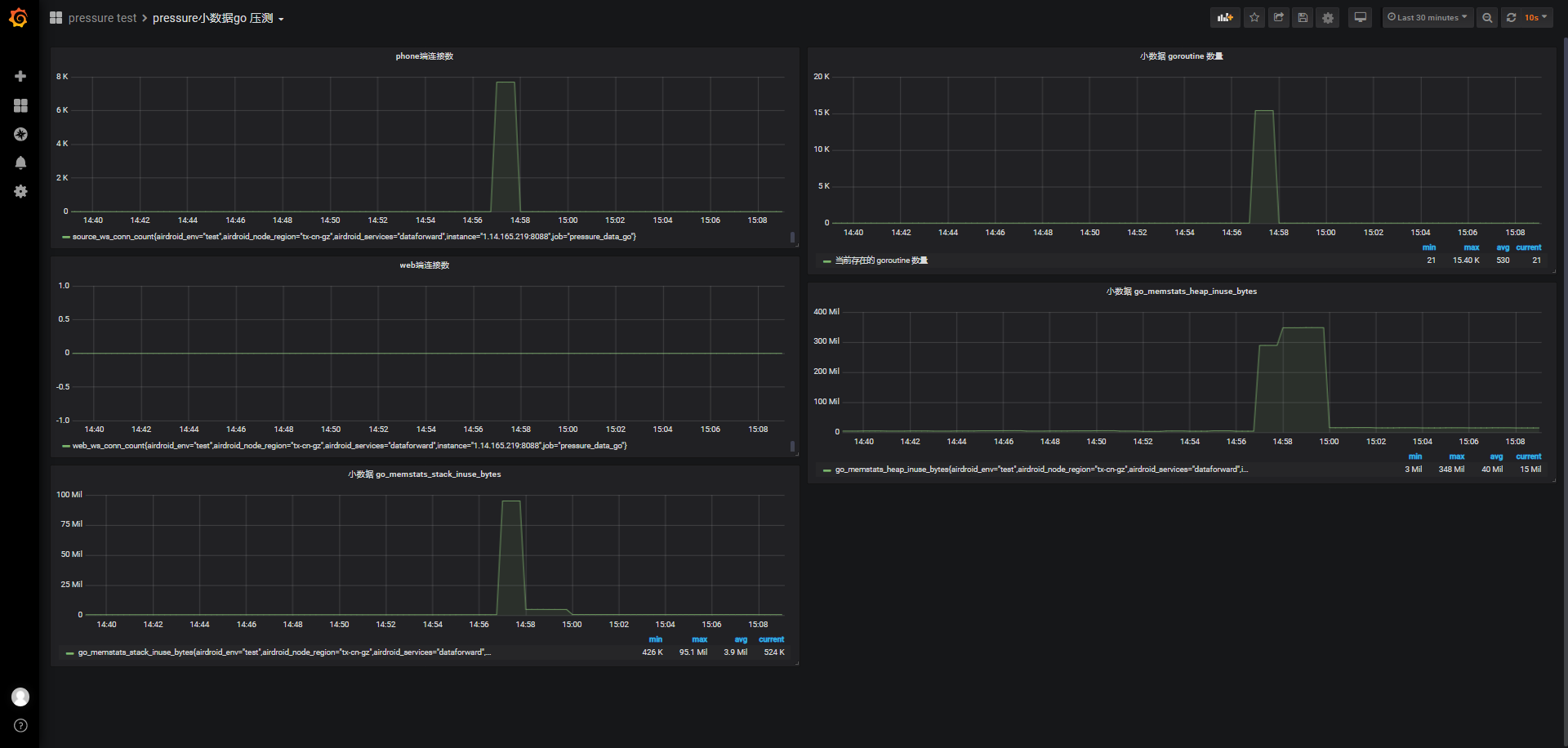
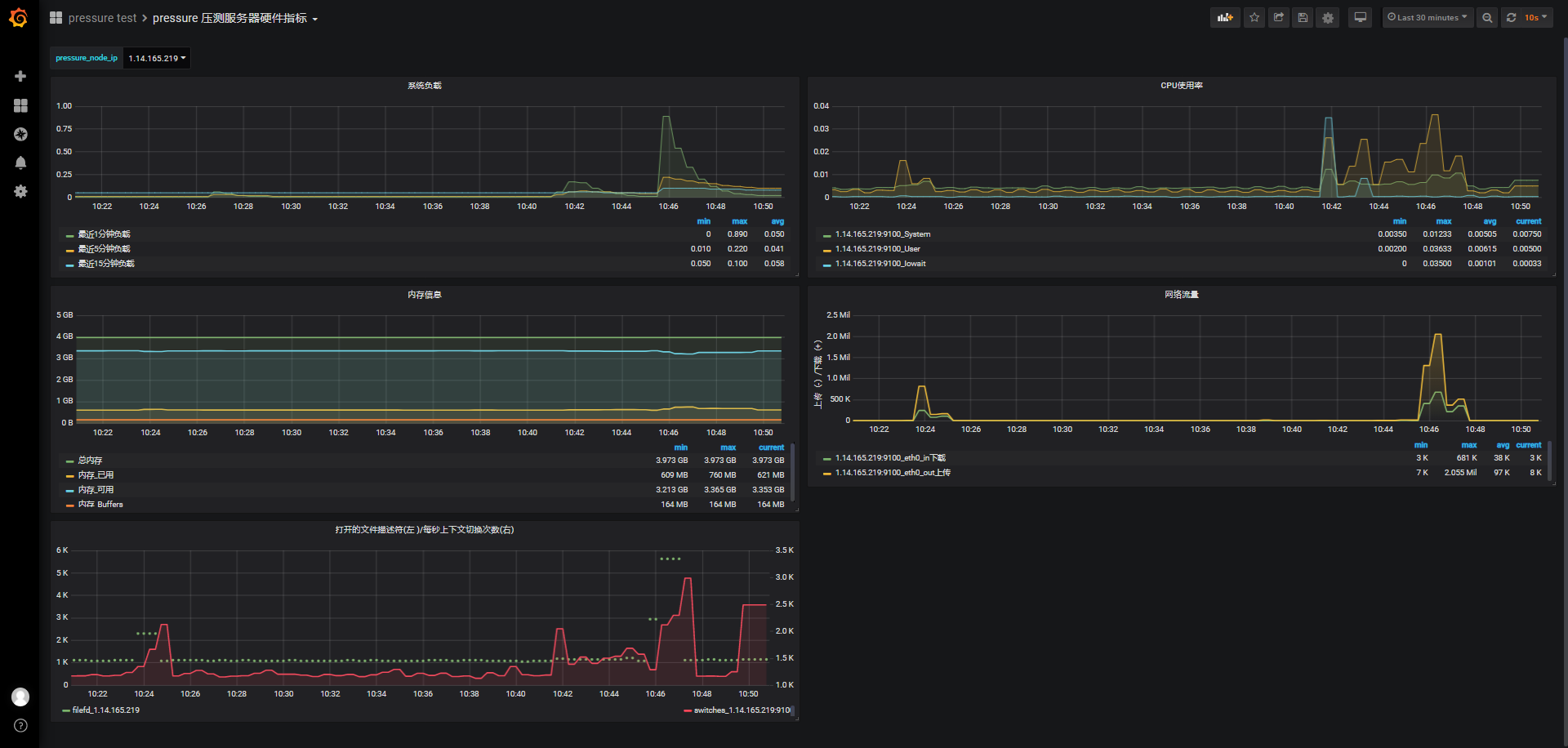
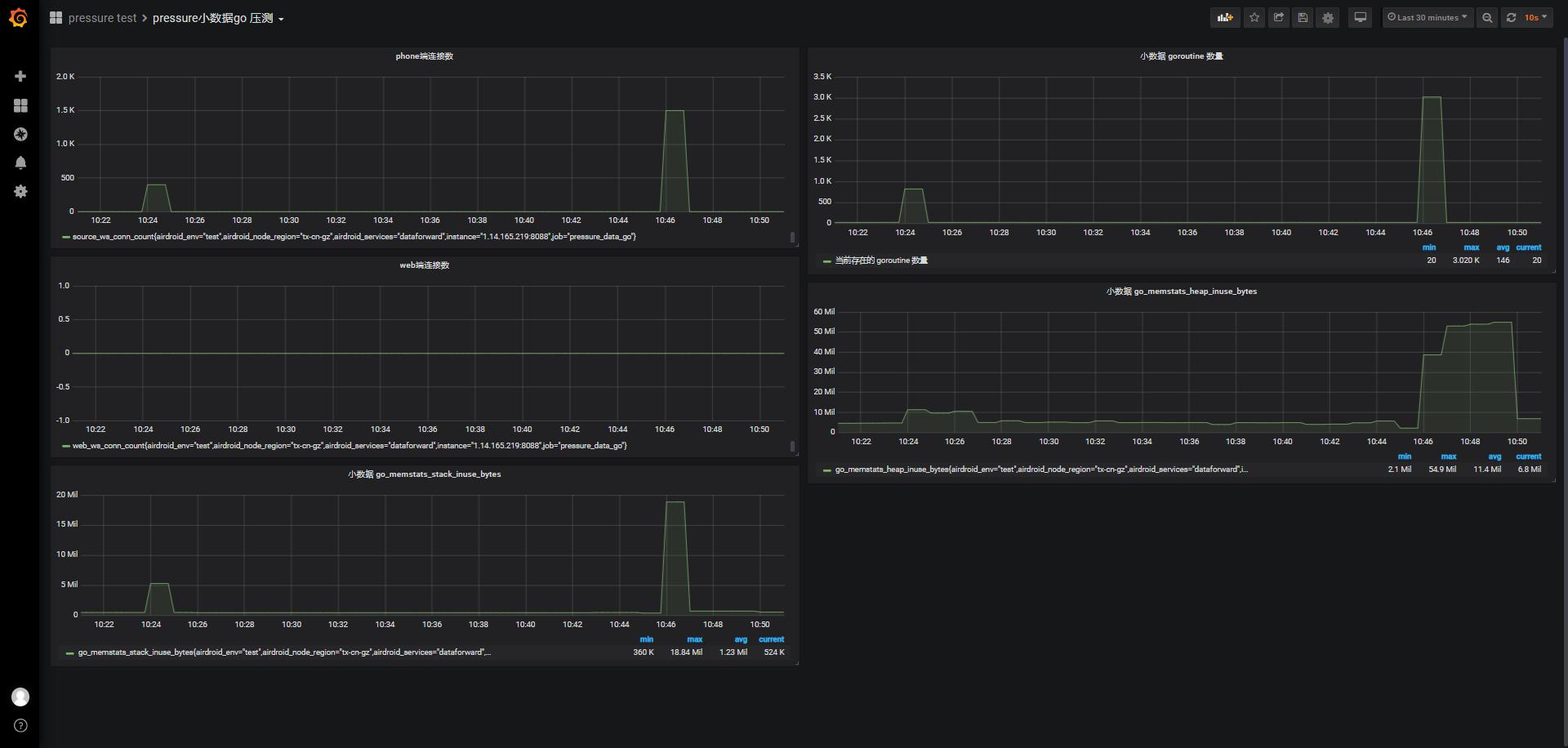
服务器与服务监测数据查看:grafana
- pressure test
- pressure压测服务器硬件指标
- pressure小数据go压测
- pressure test
-
id
文中每组测试都会有个id。由于每个场景会有多组测试,每组测试可能会有多次测试,为方便识别及找到对应jmeter报告与grafana监测数据,可以通过id上的时间段去找对应的报告和监测图表。
-
Apdex
Apdex意义在于:
- 一个满意样本得分为:1
- 一个容忍样本得分为:0.5
- 一个失望样本得分为:0
可以认为Apdex =(1 × 满意samples + 0.5 × 容忍samples)÷ samples总数
服务器资源
被测服务:wssrv
-
协议
- wss
-
端口
- 9088
- 443转8088
-
被压测服务器
- 2核4G
-
压力机
- 2核4G 6台
-
控制机
- 2核8G 1台 ,也能作为部分压力机
服务器都是腾讯云服务器。
具体分布式压力部署详见wssrv压测计划、wssrv压测过程记录、wssrv压测jmx配置文件
wss配置
-
wssrv服务配置文件
除了默认的8088端口,再启用9088端口支持wss协议请求,redis服务外置:
[Common] port=8088 pprofPort=0.0.0.0:6062 sslEnable=true enableConn=true dataFlowSyncInterval=5 webHeartBeatTimeout=60 phoneHeartBeatTimeout=120 phoneHeartBeatTimeoutSlow=1200 bizDaemonHeartBeatTimeoutSlow=300 kidChildHeartBeatTimeoutSlow=300 phoneHeartBeatDeviceInfoTimeout=120 phoneHeartBeatPersonalDeviceInfoTimeout=180 serverWaitExtraTime=10 urgeBizDaemonHHeartBeatTimeout=60 urgeBizDaemonHPlusHeartBeatTimeout=60 forceTls12=true [Ssl] map={"test-pressure-data.9ong.com":{"port":"9088", "key":"/etc/nginx/ssl/9ong.com.key", "crt":"/etc/nginx/ssl/9ong.com.crt"},"airdroid-cn.com":{"port":"9089", "key":"ssl/airdroid-cn.com.key", "crt":"ssl/airdroid-cn.com.crt"}} [Redis] MaxIdle=50 MaxActive=1000 IdleTimeout=120 WaitIdle=1 [RedisResque] uri= 172.16.0.7:6379 db = 4 password = [RedisDataflow] uri= 172.16.0.7:6379 db = 6 password = [RedisStatWorker] uri= 172.16.0.7:6379 db = 14 password = -
nginx ssl配置
由于是nginx转发,启用443端口,所以wssrv不需要做任何修改,只要默认开放8088端口即可。
以下运维提供配置:
map $http_upgrade $connection_upgrade { default upgrade; '' close; } upstream data{ server 127.0.0.1:8088 fail_timeout=0; } server { #listen 80; server_name test-pressure-data.9ong.com; listen 443 ssl http2; include ssl/ssl_9ong.com.conf; #include ssl/ssl_id_9ong.com.conf; #include conf.d/limitip_lan.conf; access_log /var/log/nginx/test-pressure-data.9ong.com.access.log main; access_log /var/log/nginx/test-pressure-data.9ong.com.4xx5xx.log combined if=$loggable; error_log /var/log/nginx/test-pressure-data.9ong.com.error.log warn; location / { proxy_pass http://data; proxy_read_timeout 1800s; proxy_send_timeout 1800s; proxy_set_header Host $host; proxy_set_header X-Real-IP $remote_addr; proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; proxy_http_version 1.1; proxy_set_header Upgrade $http_upgrade; proxy_set_header Connection "upgrade"; } }ssl_id_9ong.com.conf
ssl_certificate ssl/9ong.com.crt; ssl_certificate_key ssl/9ong.com.key; ssl_session_timeout 5m; ssl_protocols TLSv1 TLSv1.1 TLSv1.2 TLSv1.3; #ssl_protocols TLSv1 TLSv1.1 TLSv1.2 TLSv1.3; #支持TLSv1.2 版本的高强度加密 #ssl_ciphers ECDHE-RSA-AES256-GCM-SHA512:DHE-RSA-AES256-GCM-SHA512:ECDHE-RSA-AES256-GCM-SHA384:DHE-RSA-AES256-GCM-SHA384:ECDHE-RSA-AES256-SHA384:ECDHE-RSA-AES128-SHA256:ECDHE-RSA-AES256-SHA:ECDHE-RSA-AES128-SHA:RSA-AES256-SHA:RSA-AES128-SHA; #ssl_ciphers ECDHE-RSA-AES256-GCM-SHA512:DHE-RSA-AES256-GCM-SHA512:ECDHE-RSA-AES256-GCM-SHA384:DHE-RSA-AES256-GCM-SHA384:ECDHE-RSA-AES256-SHA384:ECDHE-RSA-AES128-SHA256; #ssl_ciphers ECDHE-RSA-AES256-GCM-SHA512:DHE-RSA-AES256-GCM-SHA512:ECDHE-RSA-AES256-GCM-SHA384:DHE-RSA-AES256-GCM-SHA384:ECDHE-ECDSA-AES256-GCM-SHA384; #兼容低版本的TLSv1.0 1.1 版本加密 ssl_ciphers EECDH+AESGCM:EDH+AESGCM:AES256+EECDH:AES256+EDH:ECDHE-RSA-AES128-GCM-SHA384:ECDHE-RSA-AES128-GCM-SHA256:ECDHE-RSA-AES128-GCM-SHA128:DHE-RSA-AES128-GCM-SHA384:DHE-RSA-AES128-GCM-SHA256:DHE-RSA-AES128-GCM-SHA128:ECDHE-RSA-AES128-SHA384:ECDHE-RSA-AES128-SHA128:ECDHE-RSA-AES128-SHA:ECDHE-RSA-AES128-SHA:DHE-RSA-AES128-SHA128:DHE-RSA-AES128-SHA128:DHE-RSA-AES128-SHA:DHE-RSA-AES128-SHA:ECDHE-RSA-DES-CBC3-SHA:EDH-RSA-DES-CBC3-SHA:AES128-GCM-SHA384:AES128-GCM-SHA128:AES128-SHA128:AES128-SHA128:AES128-SHA:AES128-SHA:DES-CBC3-SHA:HIGH:!aNULL:!eNULL:!EXPORT:!DES:!MD5:!PSK:!RC4; ssl_prefer_server_ciphers on;
压力机hosts解析
压力机需要配置/etst/hosts
127.0.0.1 localhost
172.16.0.14 test-pressure-data.9ong.com
#1.14.165.219 test-pressure-data.9ong.com
1.14.165.219 外网ip,外网测试时使用。
SSL握手延迟
#!/bin/sh
curl --include \
--no-buffer \
--header "Connection: Upgrade" \
--header "Upgrade: websocket" \
--header "Host: websocketclient.9ong.com" \
--header "Origin: https://websocketclient.9ong.com" \
--header "Sec-WebSocket-Key: websocket-key" \
--header "Sec-WebSocket-Version: 13" \
-w "TCP handshake: %{time_connect}, SSL handshake: %{time_appconnect}\n" -so /dev/null \
https://test-pressure-data.9ong.com:9088
执行这个shell脚本查看tcp与ssl握手分别花费的时间:
-
开发测试环境
test-cn-1-data.9ong.com
9088端口云上测试结果:
TCP handshake: 0.033251, SSL handshake: 0.092561
-
压测测试环境(内网)
test-pressure-data.9ong.com
9088内网测试结果:
TCP handshake: 0.000683, SSL handshake: 0.009622
443内网测试结果:
TCP handshake: 0.000713, SSL handshake: 0.008883
-
压测测试环境(外网)
test-pressure-data.9ong.com
9088端口测试结果:
TCP handshake: 0.003436, SSL handshake: 0.017418
443端口测试结果:
TCP handshake: 0.003503, SSL handshake: 0.016612
ssl握手花费较多时间,一般取决于网络状况和cpu,一般场合采用1024位证书,如果更大位数的证书,握手时间会更长,cpu消耗也会更多些。我们采用2048位的RSA加密算法,时间也相对会长些。
wss连接,除了TCP握手外,还需要考虑SSL握手延迟,根据前面握手时间的了解,wss连接比ws连接时间要多出不少时间,内网压测测试环境TCP与SSL握手时间比差不多在1:10+。
方式一、wss直连
并发连接
场景:
phone端并发连接,瞬间并发,连接成功后,每30秒发一次心跳,维持3次后,1至5s后关闭。
希望找出可最大并发连接数。
尝试了这些并发量:
如果仅仅考虑单个连接的话,可以先按4倍来估算,从1w并发开始。
-
1w
id:wss-connect-10000-1028-1456
并发连接时我们看到有不少连接错误:
Starting distributed test with remote engines: [172.16.0.12:1099, 172.16.0.8:1099, 172.16.0.3:1099, 172.16.0.2:1099, 172.16.0.16:1099] @ Thu Oct 28 14:56:56 CST 2021 (1635404216186) Remote engines have been started:[172.16.0.12:1099, 172.16.0.8:1099, 172.16.0.3:1099, 172.16.0.2:1099, 172.16.0.16:1099] Waiting for possible Shutdown/StopTestNow/HeapDump/ThreadDump message on port 4445 summary + 706 in 00:00:03 = 210.5/s Avg: 884 Min: 49 Max: 2021 Err: 0 (0.00%) Active: 1120 Started: 1038 Finished: 0 summary + 15400 in 00:00:30 = 514.4/s Avg: 3164 Min: 0 Max: 14501 Err: 2311 (15.01%) Active: 10000 Started: 9918 Finished: 0 summary = 16106 in 00:00:33 = 483.8/s Avg: 3064 Min: 0 Max: 14501 Err: 2311 (14.35%) summary + 14600 in 00:00:30 = 486.7/s Avg: 0 Min: 0 Max: 6 Err: 4622 (31.66%) Active: 9968 Started: 9918 Finished: 32 summary = 30706 in 00:01:03 = 485.2/s Avg: 1607 Min: 0 Max: 14501 Err: 6933 (22.58%) summary + 19294 in 00:00:21 = 932.2/s Avg: 0 Min: 0 Max: 45 Err: 4622 (23.96%) Active: 0 Started: 9918 Finished: 10000 summary = 50000 in 00:01:24 = 595.3/s Avg: 987 Min: 0 Max: 14501 Err: 11555 (23.11%) Tidying up remote @ Thu Oct 28 14:58:20 CST 2021 (1635404300808) ... end of run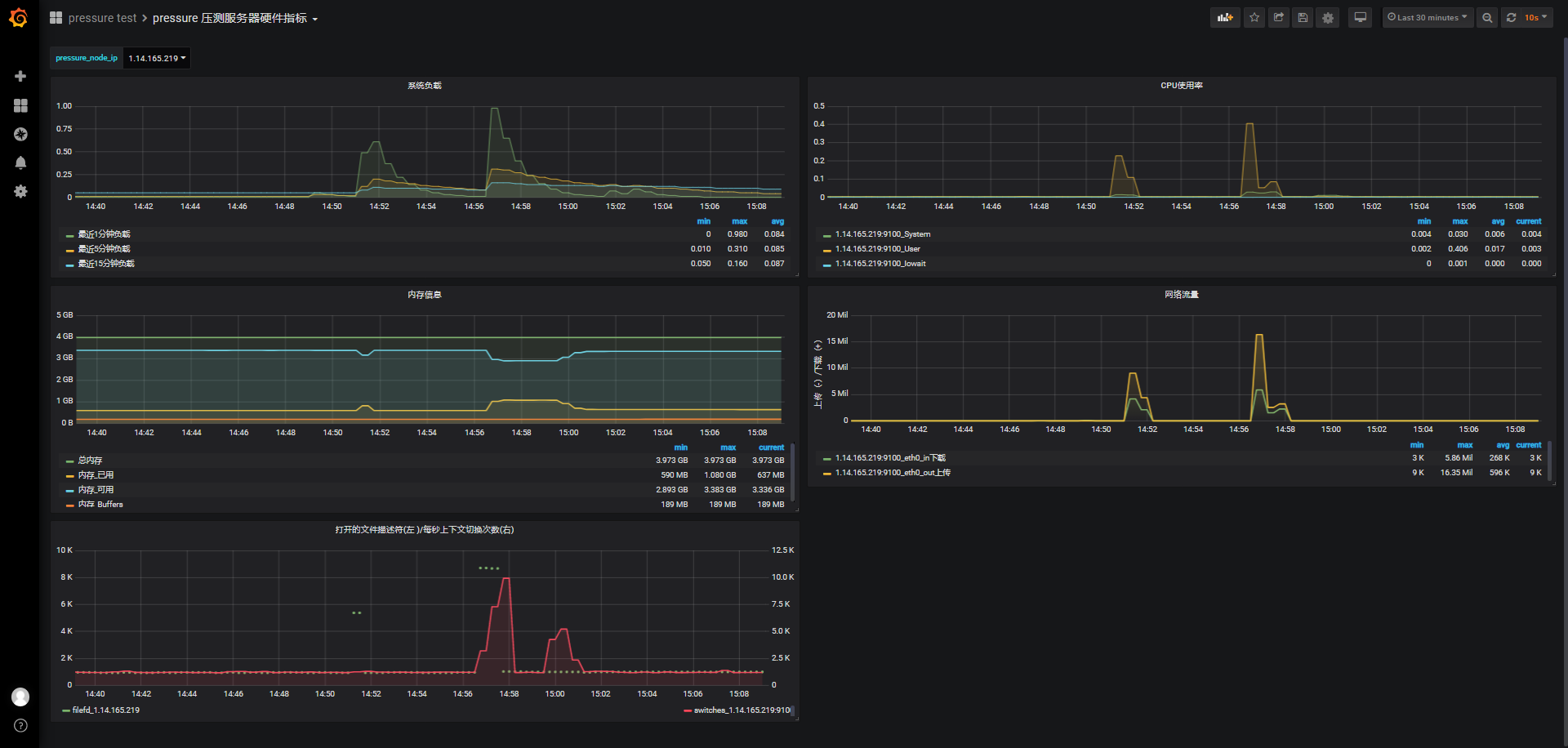
-
7500
id:wss-connect-7500-1028-1517
过去15分钟内,我们尝试了3次7500并发连接,看起来效果也不是很好,失败率在20%~35%,服务器状态良好,主要是客户端连接超时,报告概览看90%的连接响应时间在10s以下:
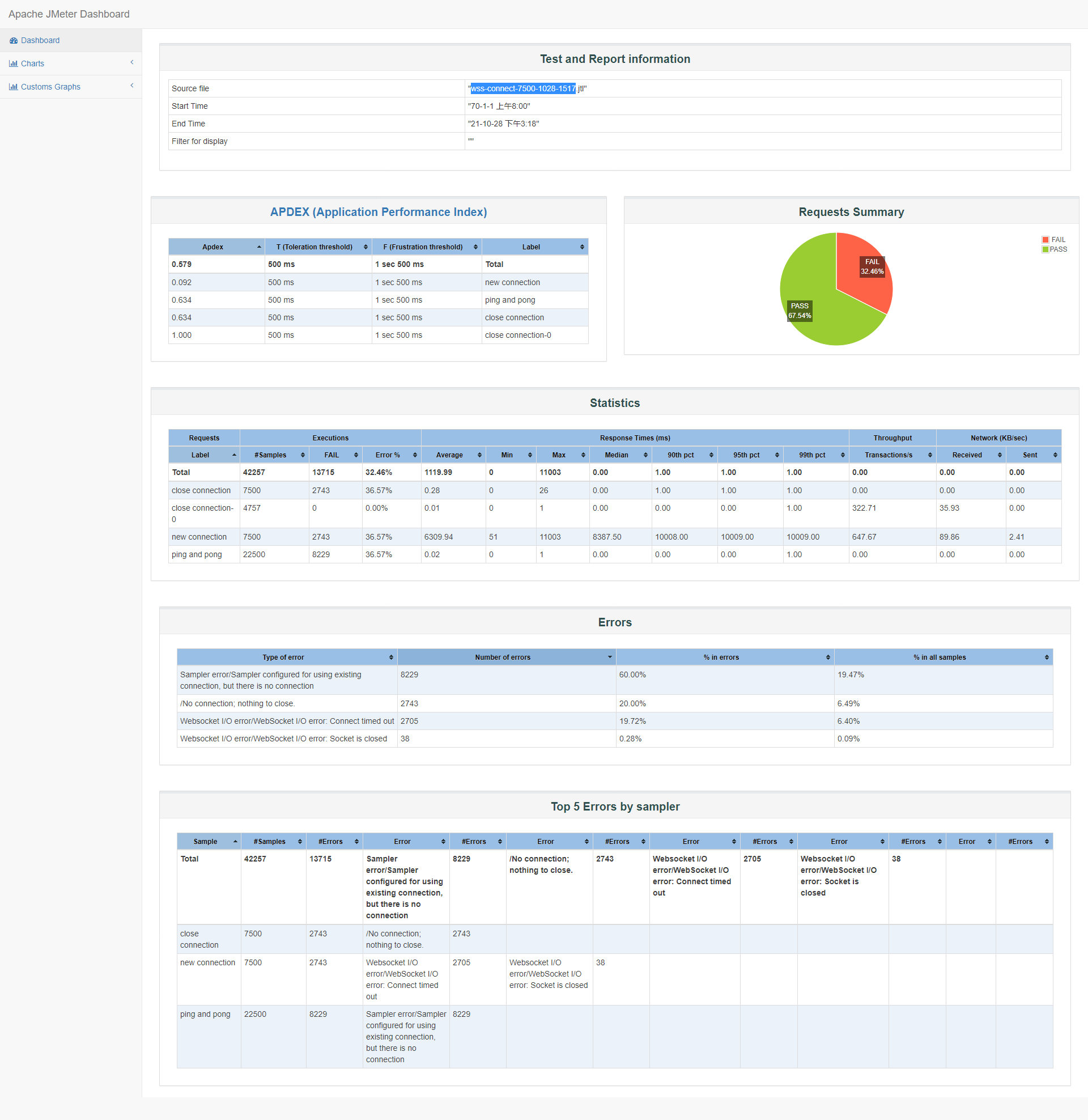
服务器监测数据略。
-
5000
id:wss-connect-5000-1028-1541
监测数据略。
从报告概览中,观察到90%的响应时间并没有明显下降,但50%的客户端响应时间比7500并发连接下降了非常多。
-
4000
4000并发时,还有接近10%的超时,还是先考虑3000并发吧
-
3000
还有7%(229个)左右的超时
-
2500
2500并发时可以达到100%并发成功,所以又做了几组2500并发,有一两组出现1%的超时,这里贴最新的一组成功率100%的报告概览:
id:wss-connect-2500-1028-1629
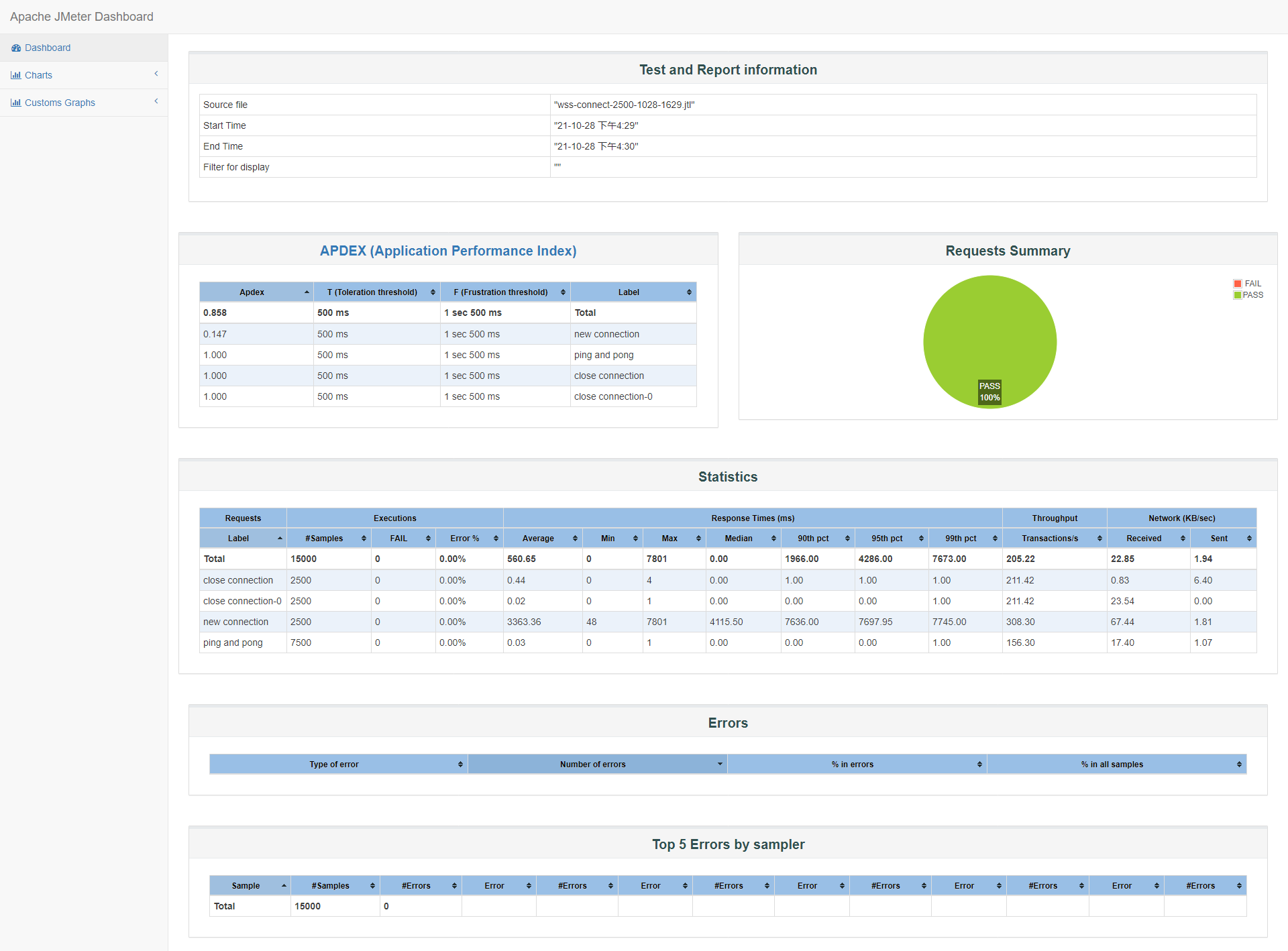
-
2000
id:wss-connect-2000-1028-1747
-
1500
id:wss-connect-1500-1028-1805
-
1250
id:wss-connect-1250-1028-1819
-
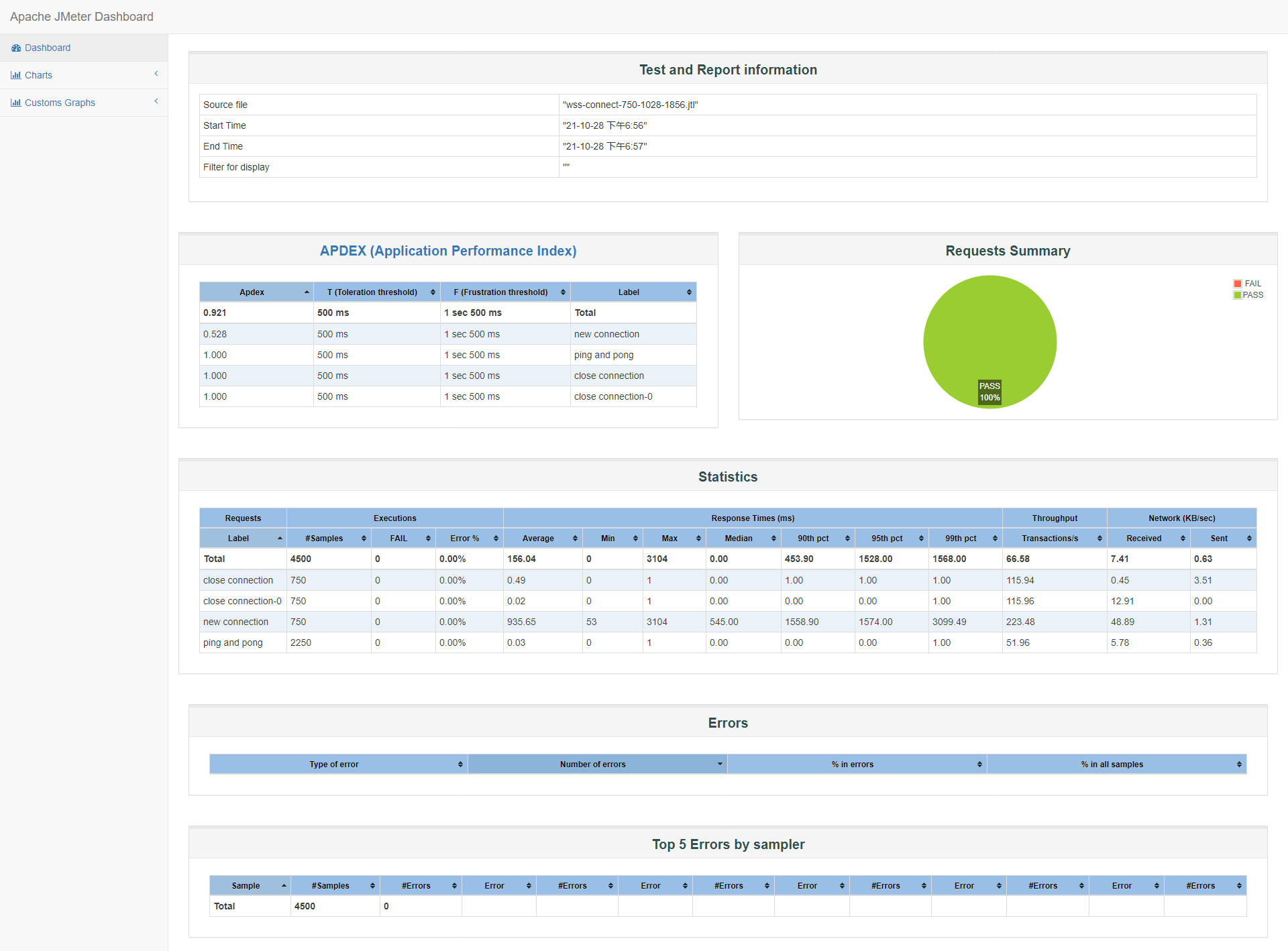
750
id:wss-connect-750-1028-1856
直到750并发时,90%的客户端响应时间在3s以下(1558ms),满意度Apdex在0.5左右:
-
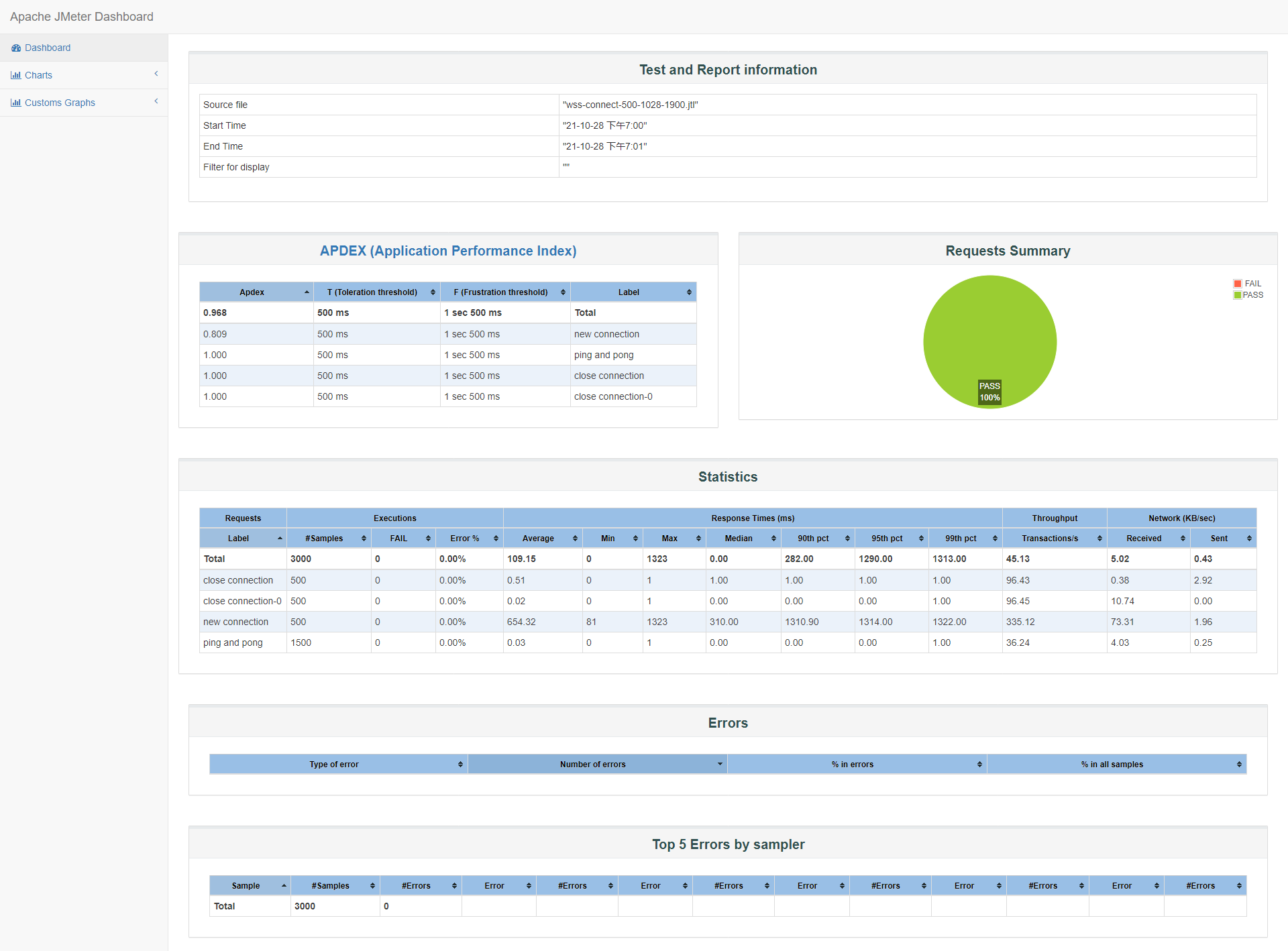
500
id:wss-connect-500-1028-1900
500并发满意度提升到了0.809,说明更多连接可以在更多的时间内完成,其他数据与750并发差不多:
-
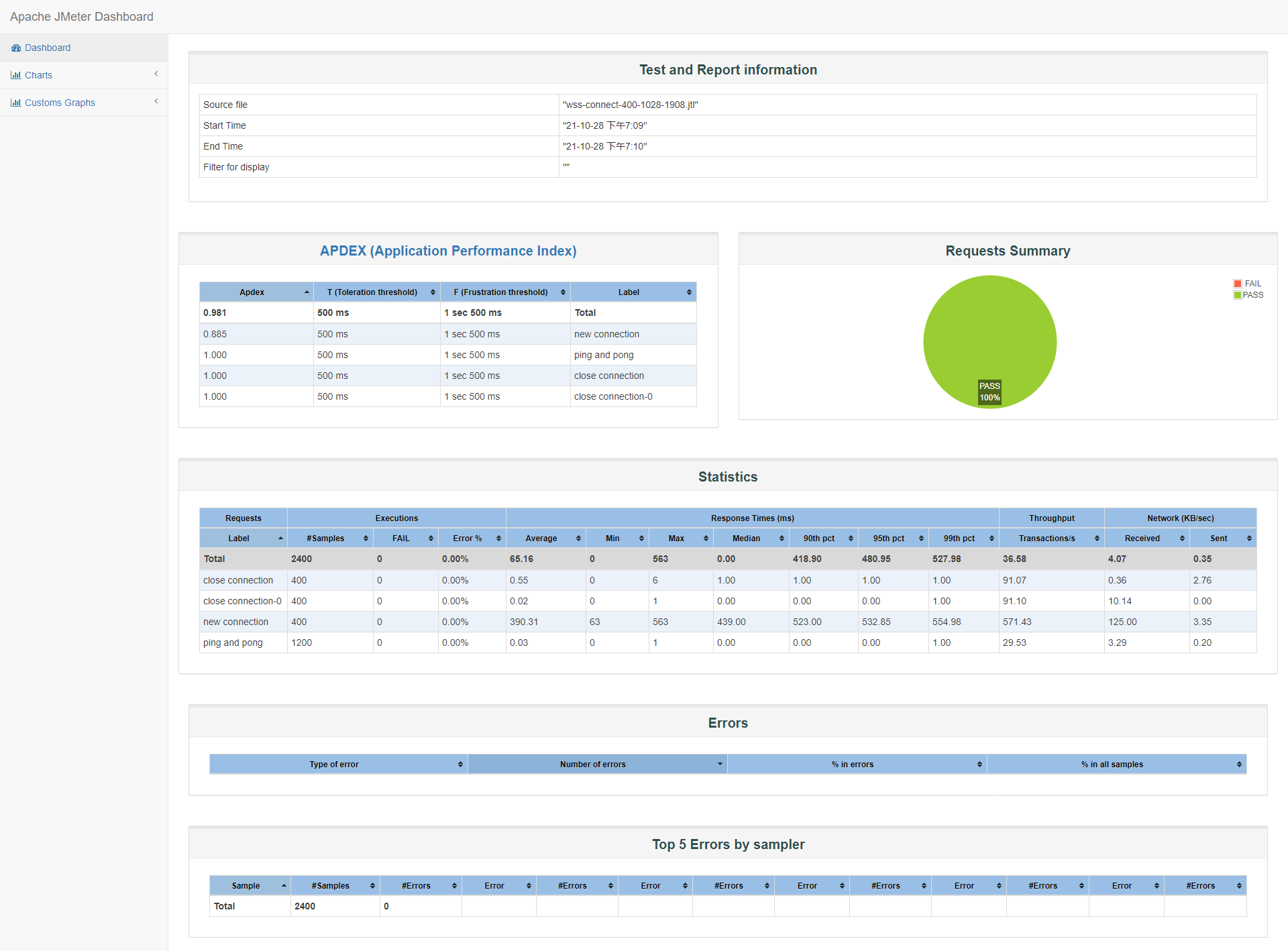
400
id:wss-connect-400-1028-1908
下降到400并发时,也测试了几组,小结中贴了一组最差的和一组最新的。最新的90%的客户端响应时间终于下降到1s以下,接近500ms以下,满意度Apdex也提升到0.885,TPS也高达571:
关于wss直连并发测试结果,服务器负载低,cpu、内存使用率低,没有太大波动,如果有需要查看可以根据id到grafana上根据时间段查看,每组测试结果数据比对详见小结。
小结:
| 并发数 | samples | failed | error | median | 90th pct | TPS | Apdex |
|---|---|---|---|---|---|---|---|
| 2500 | 2500 | 37 | 1.48% | 4170.00 | 7790.00 | 239.39 | 0.137 |
| 2000 | 2000 | 0 | 0.00% | 1669.00 | 7452.90 | 249.69 | 0.234 |
| 1500 | 1500 | 0 | 0.00% | 1229.50 | 3440.00 | 388.20 | 0.328 |
| 1250 | 1250 | 0 | 0.00% | 1689.00 | 3274.90 | 350.53 | 0.278 |
| 1000 | 1000 | 0 | 0.00% | 1648.00 | 3369.90 | 277.70 | 0.357 |
| 750 | 750 | 0 | 0.00% | 545.00 | 1558.90 | 223.48 | 0.528 |
| 500 | 500 | 0 | 0.00% | 310.00 | 1310.90 | 335.12 | 0.809 |
| 400 | 400 | 0 | 0.00% | 304.50 | 1146.00 | 301.20 | 0.879 |
| 400 | 400 | 0 | 0.00% | 439.00 | 523.00 | 571.43 | 0.885 |
从上表格,可以观察到:从2500并发(尝试了几组有完全成功的,也有1%左右的超时)开始能完成所有并发连接,但连接响应时间不令人满意,也就是90%的客户端响应时间太长,TPS也不高;随着并发梯度下降到750并发,90%的客户端响应时间才在1500ms以下,直到400并发时,90%的客户端响应时间大约在500ms以下,Apdex客户满意指数达到0.885(1表示所有用户满意)。
单个wss连接可能只比ws连接慢个3到10倍,但一旦并发,整体连接时间会成一定比例或对数上涨。
更多比对数据会在方式二nginx+wss测试后给出。
阶梯连接
场景:
phone端阶梯连接,30秒(或最大150秒)内完成所有用户连接,每10~30秒随机心跳,维持10次后,1~10秒关闭.
希望找出服务器可支持的最大连接数。
尝试了这些连接数量:
-
1w/30s
在前30秒发起连接时,负载最高0.54 ,CPU使用率达到0.3;连接前系统可用内存3.372G,保持连接期间,可用内存保持在2.71G,直到连接陆续断开,1w连接消耗了668M。
-
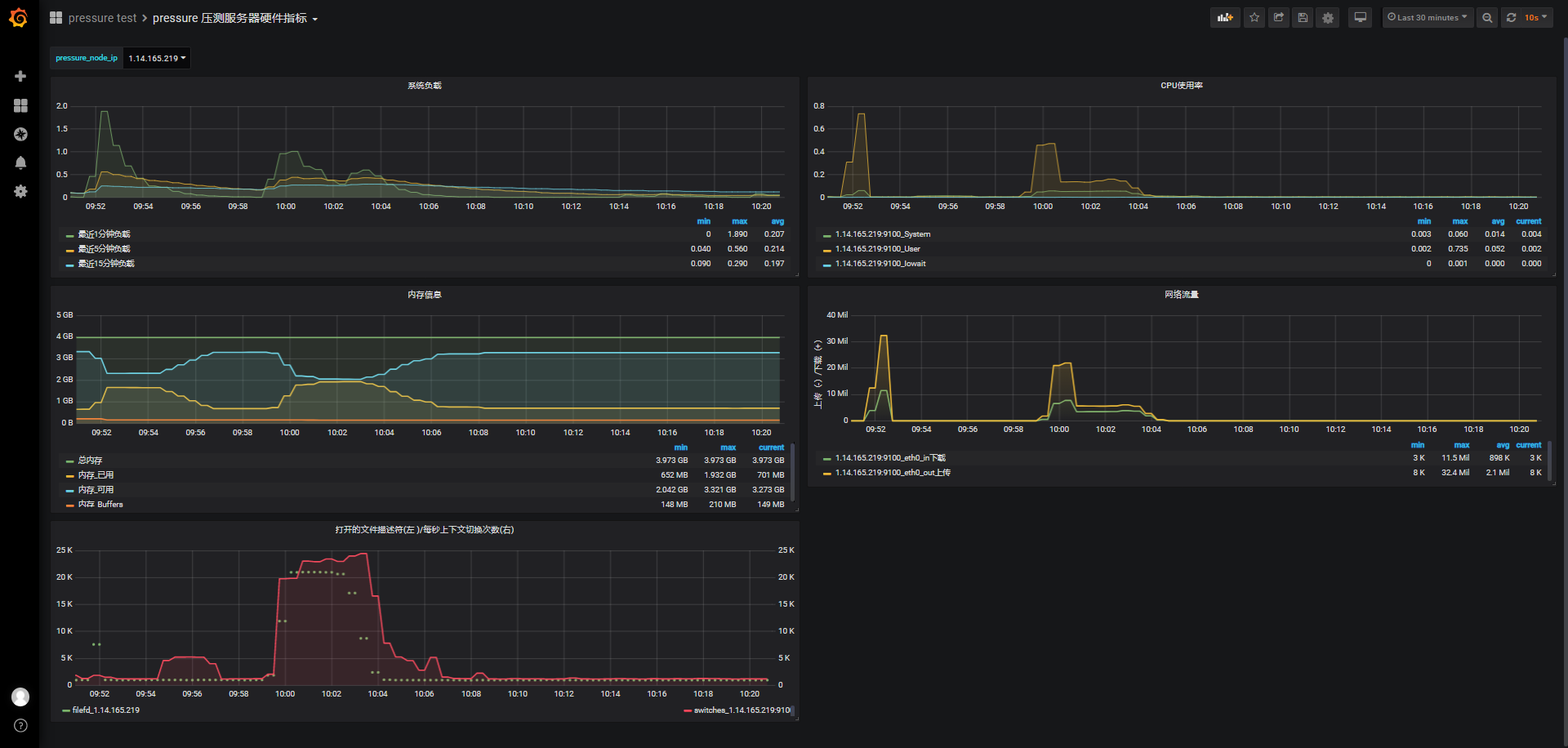
2w/60s
id:wss-connect-rampup-10000-1029-0929
在前60秒连接期间,负载最高接近1,在维持心跳期间负载回落到0.5以下,心跳结束后,TCP挥手断开连接,客户端主动断开连接时,负载略微上升;用户态CPU使用率达到0.5,相比较于ws协议的连接,wss协议对cpu的使用会略高。
连接前剩余3.29G可用内存,保持连接期间可用内存剩余2.04G,2W连接消耗1280M内存。
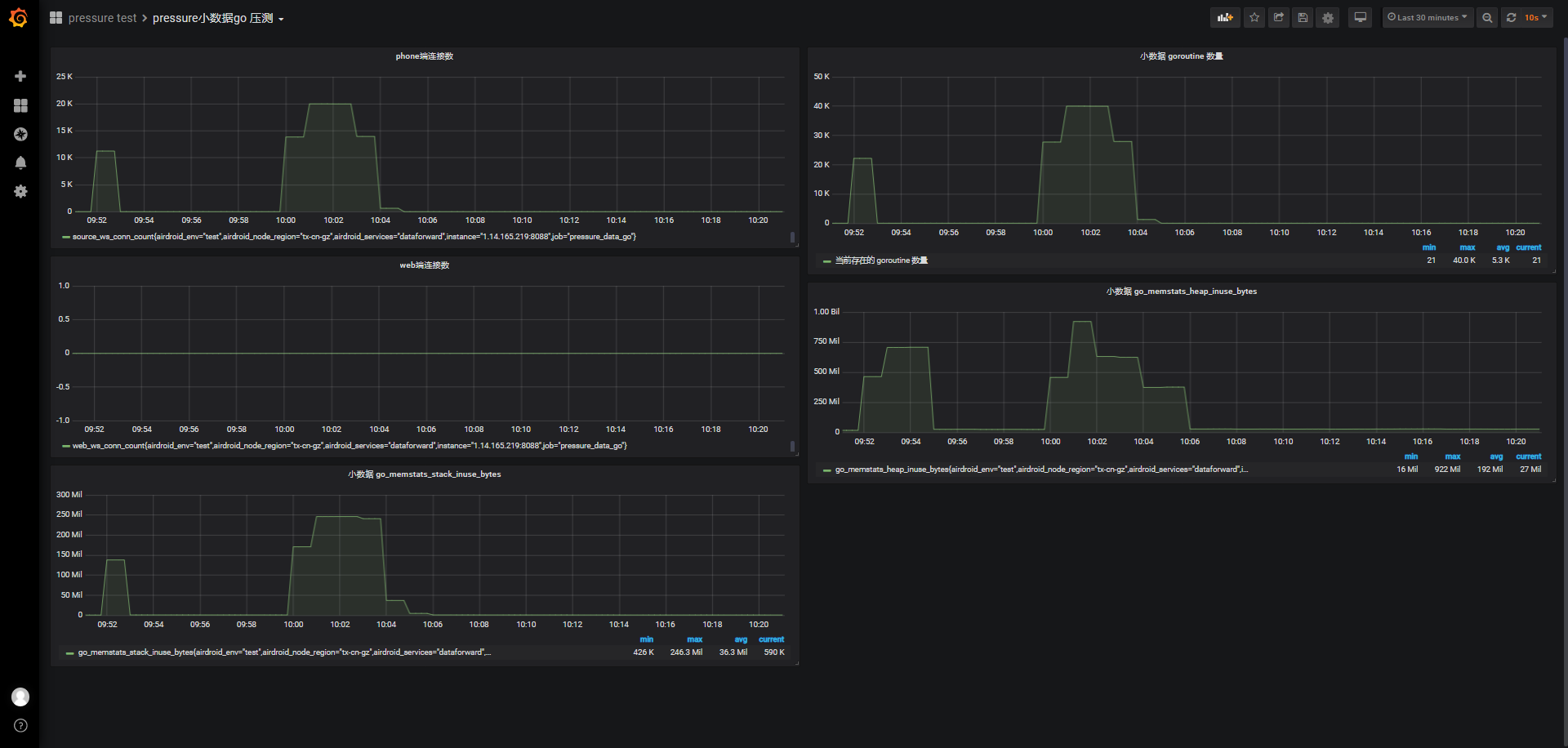
由于是阶梯连接,客户端响应时间都在500ms以下,Apdex指数基本为1,但TPS都在330+左右,前面并发连接已经有了解过,虽然阶梯连接时jmeter报告概览意义不太大,但后续更大连接数时会再贴上。
-
4w/120s
id:wss-connect-rampup-40000-1029
根据之前ws协议的最大可连接数测试,及前面1w、2w的测试后的服务器状态,我们考虑直接测试4w的连接数
虽然是120s内阶梯发起4w个,但在这段时间,负载明显攀升到2左右,之后才开始缓慢下降,这段时间内的cpu使用率也从0来到0.56左右,之后缓慢下降;连接前可使用内存3.425G,保持连接期间最低可使用内存剩余782M,换算下,4w连接大约消耗2725M内存
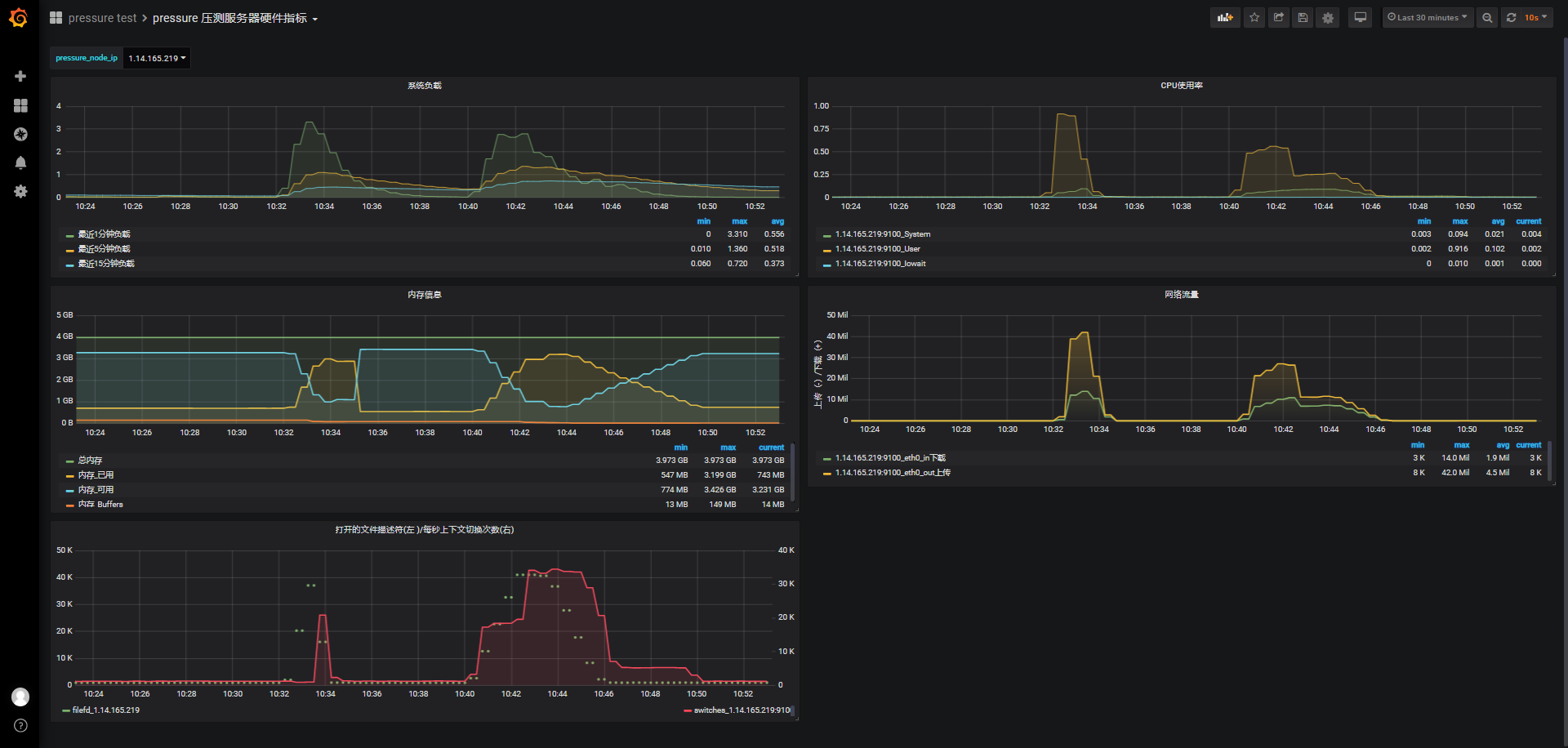
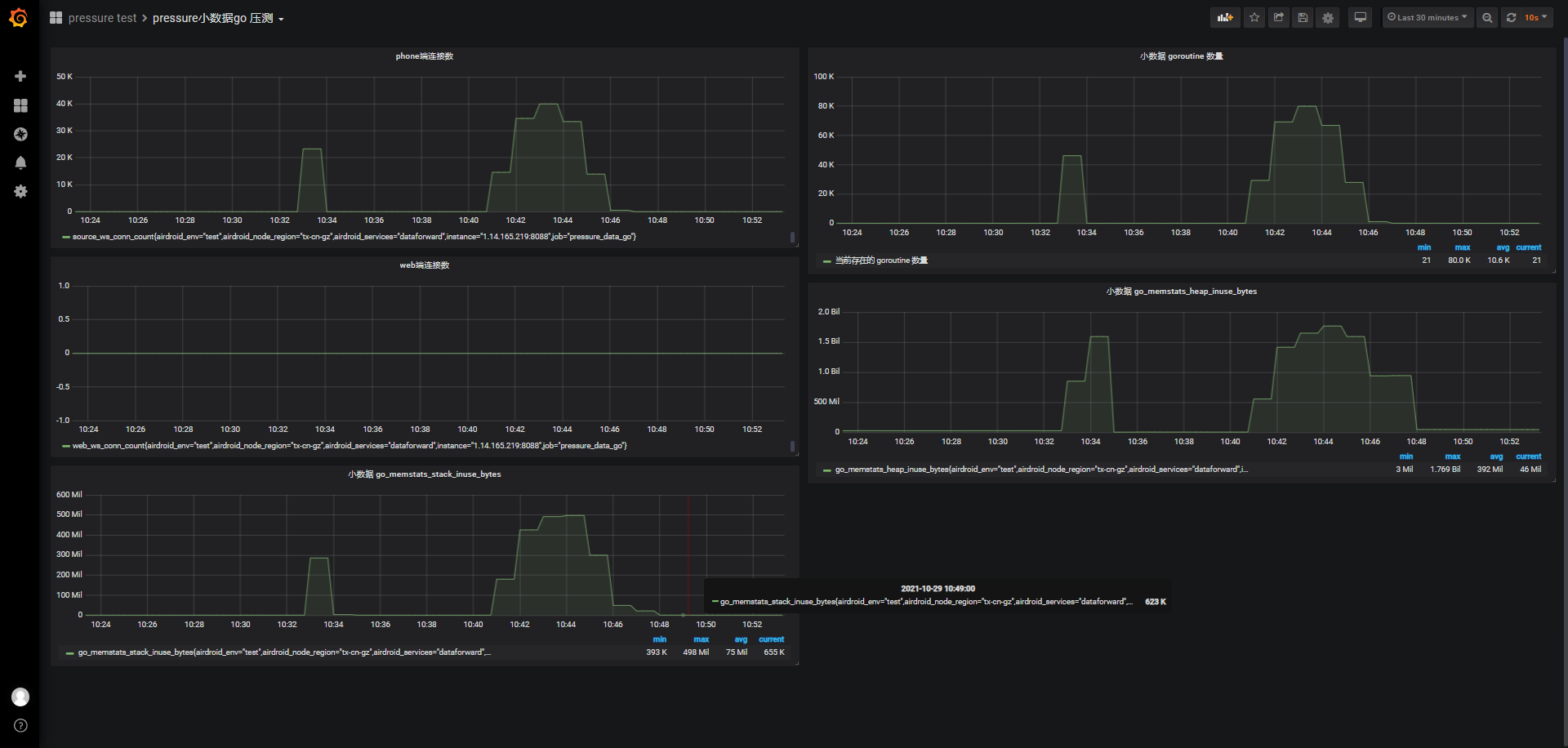
客户端响应时间和TPS,因为连接时在阶梯上涨的,所以响应时间、客户端满意指数Apdex、TPS参考意义不大,但我们可以了解这种情况下的客户端连接感受:
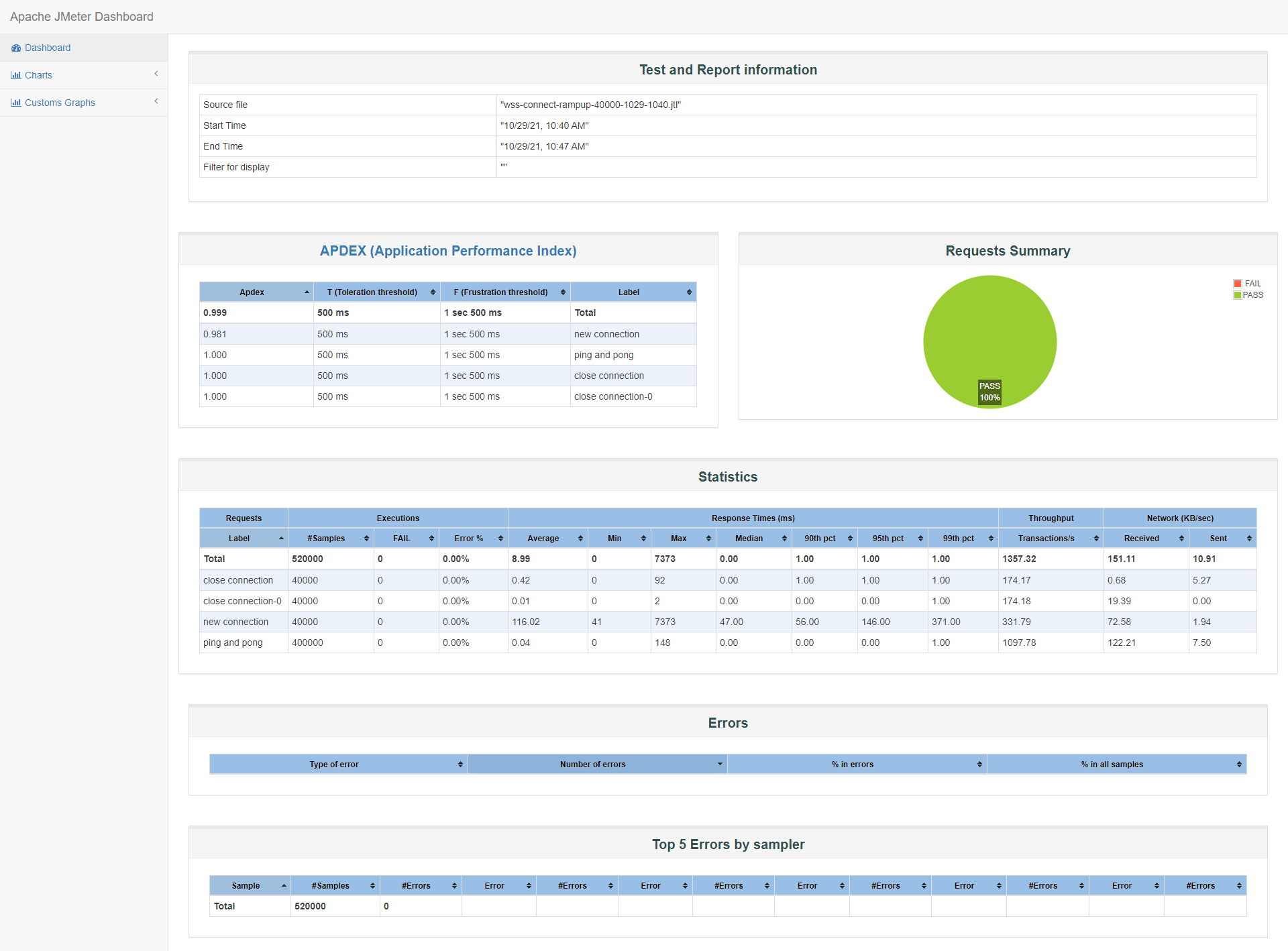
-
5w/150s
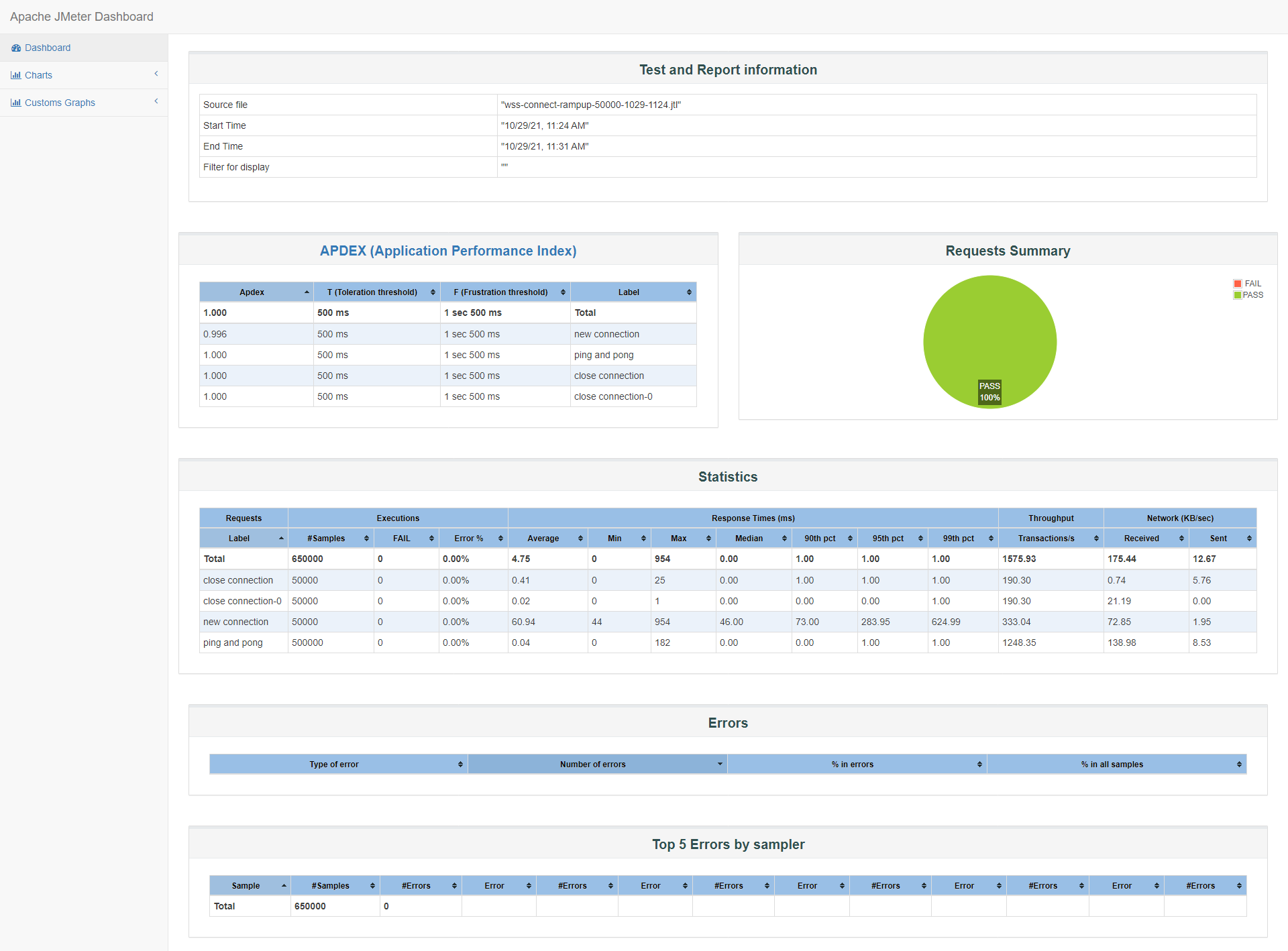
id:wss-connect-rampup-50000-1029-1124
同样的,不考虑并发,我们在150s内完成5w个连接,从监测图上可以看到期间负载逐渐上升到2.5左右,随着连接的完成也缓慢下降到正常状态,cpu使用率也很快接近0.6,在连接结束后迅速回落到0.3左右。
连接前的可用内存3.372G,保持连接期间,系统最低可用内存剩余126M,5w连接消耗了3327M内存,结合前面几次内存消耗情况,一个phone端的连接保持大概占用68k左右内存。
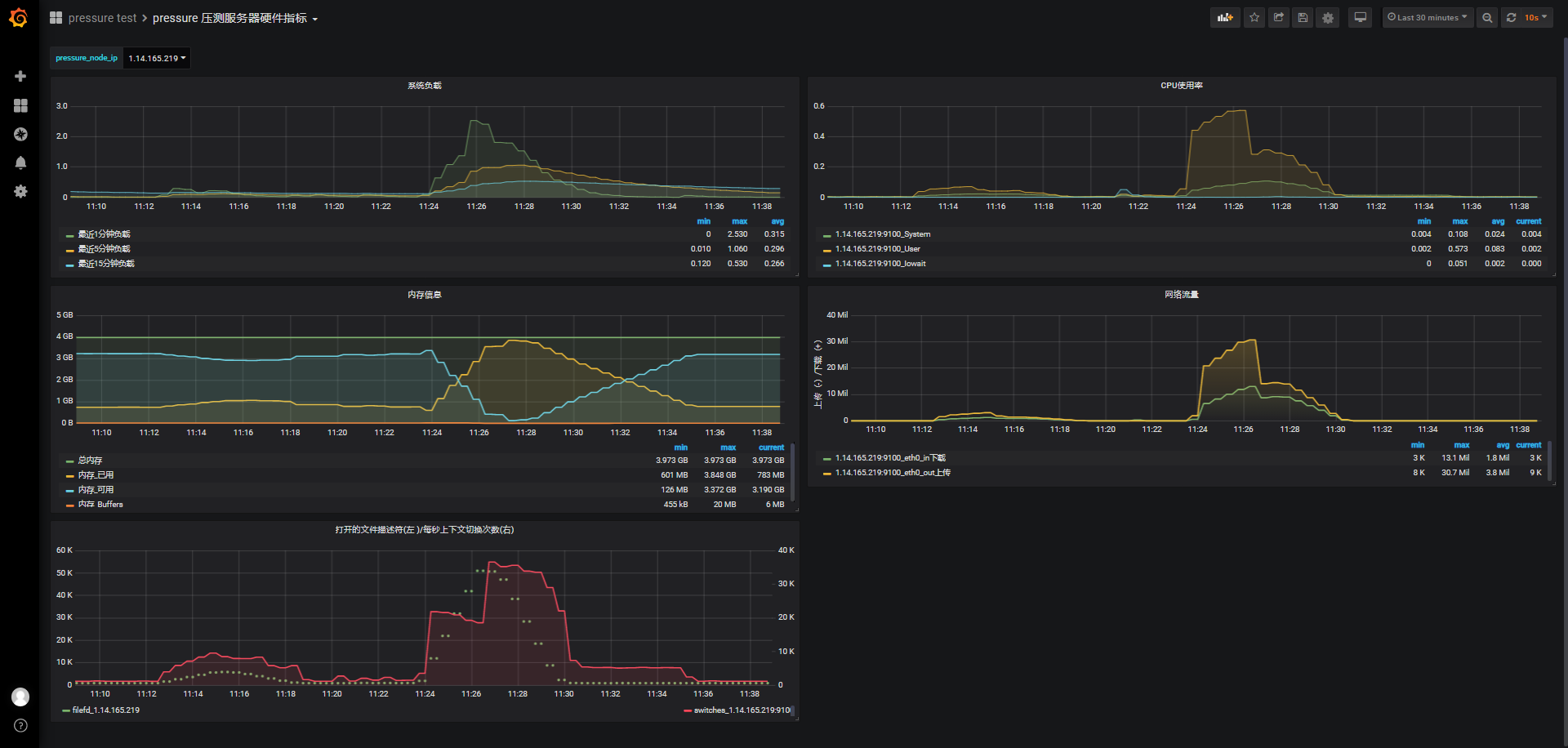
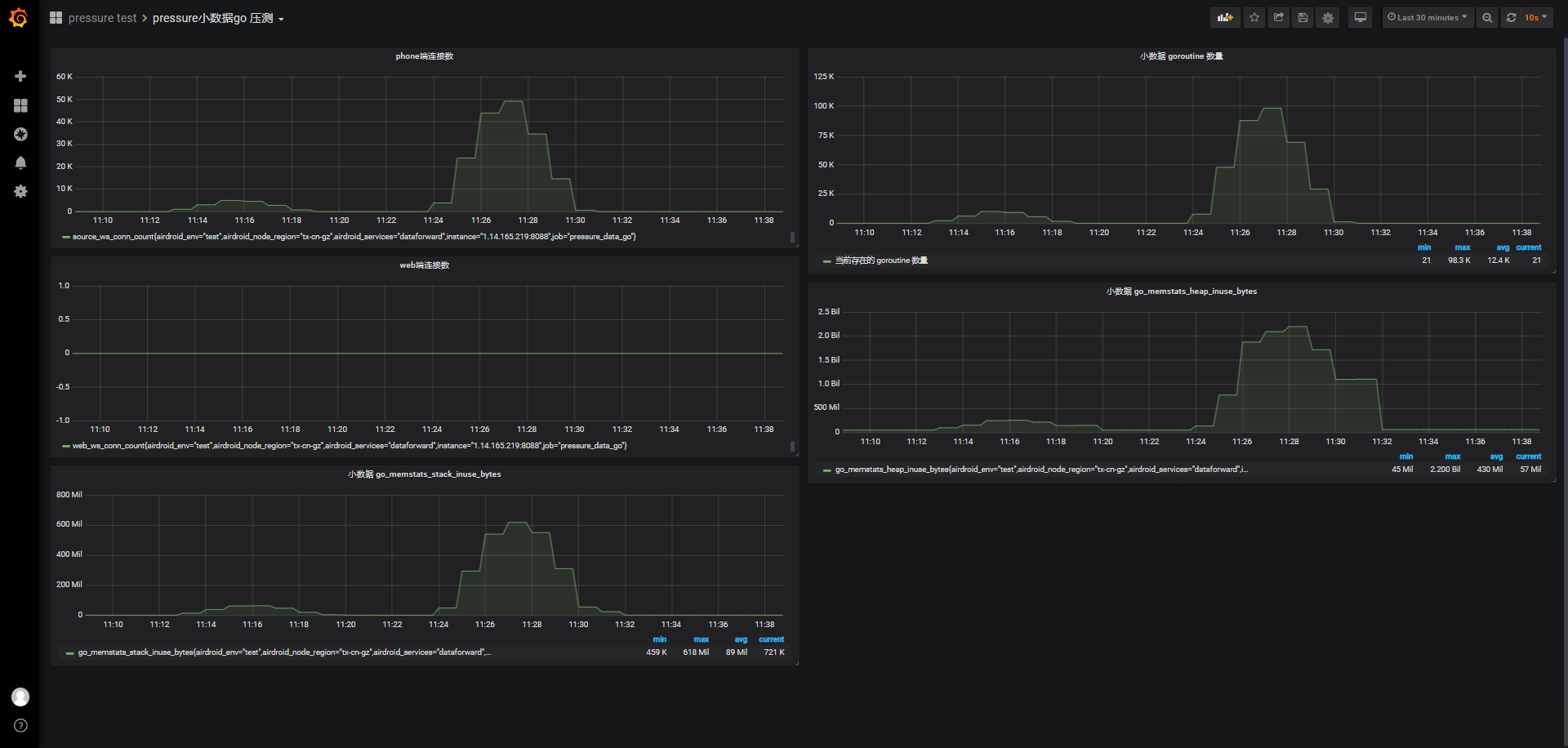
另外:连接关闭后系统已使用内存783M,重启被测服务后,系统已使用内存524M,也就是被测服务在连接过后保持一段时间后关闭连接,服务占用259M内存,晚会再测试其他连接数下同样条件下占用内存情况。
jmeter客户端报告概览:
-
5.16w/150s
id:wss-connect-rampup-51600-1029-1223
重启被测服务,释放内存,系统可用内存3.449G,已使用内存525M。
根据5w的测试结果,初步估算在5.2w连接会出现OOM,但根据之前测试ws的经验,应该会提前OOM,所以测试了5.16w的连接数。我们大概知道再连接一些用户,服务器内存就不够了。
150s阶梯连接5.16w并保持10次心跳,最后被压测服务被系统kill掉了,后续的操作都Err了:
Starting distributed test with remote engines: [172.16.0.12:1099, 172.16.0.8:1099, 172.16.0.3:1099, 172.16.0.17:1099, 172.16.0.2:1099, 172.16.0.16:1099] @ Fri Oct 29 12:23:46 CST 2021 (1635481426737) Remote engines have been started:[172.16.0.12:1099, 172.16.0.8:1099, 172.16.0.3:1099, 172.16.0.17:1099, 172.16.0.2:1099, 172.16.0.16:1099] Waiting for possible Shutdown/StopTestNow/HeapDump/ThreadDump message on port 4445 summary + 4007 in 00:00:13 = 317.0/s Avg: 1065 Min: 46 Max: 5751 Err: 0 (0.00%) Active: 4312 Started: 4270 Finished: 0 summary + 19700 in 00:00:30 = 655.4/s Avg: 28 Min: 0 Max: 249 Err: 0 (0.00%) Active: 14920 Started: 14878 Finished: 0 summary = 23707 in 00:00:43 = 555.2/s Avg: 203 Min: 0 Max: 5751 Err: 0 (0.00%) summary + 36000 in 00:00:30 = 1202.3/s Avg: 17 Min: 0 Max: 410 Err: 0 (0.00%) Active: 25487 Started: 25445 Finished: 0 summary = 59707 in 00:01:13 = 821.9/s Avg: 91 Min: 0 Max: 5751 Err: 0 (0.00%) summary + 52000 in 00:00:30 = 1729.4/s Avg: 16 Min: 0 Max: 782 Err: 0 (0.00%) Active: 36100 Started: 36058 Finished: 0 summary = 111707 in 00:01:43 = 1087.6/s Avg: 56 Min: 0 Max: 5751 Err: 0 (0.00%) summary + 67800 in 00:00:30 = 2259.6/s Avg: 20 Min: 0 Max: 1338 Err: 0 (0.00%) Active: 46690 Started: 46648 Finished: 0 summary = 179507 in 00:02:13 = 1352.5/s Avg: 43 Min: 0 Max: 5751 Err: 0 (0.00%) summary + 77600 in 00:00:30 = 2591.9/s Avg: 13 Min: 0 Max: 1840 Err: 0 (0.00%) Active: 51586 Started: 51558 Finished: 14 summary = 257107 in 00:02:43 = 1580.7/s Avg: 34 Min: 0 Max: 5751 Err: 0 (0.00%) summary + 78100 in 00:00:30 = 2602.4/s Avg: 0 Min: 0 Max: 17 Err: 0 (0.00%) Active: 50779 Started: 51558 Finished: 821 summary = 335207 in 00:03:13 = 1739.8/s Avg: 26 Min: 0 Max: 5751 Err: 0 (0.00%) summary + 79500 in 00:00:30 = 2651.9/s Avg: 0 Min: 0 Max: 10 Err: 0 (0.00%) Active: 45070 Started: 51558 Finished: 6530 summary = 414707 in 00:03:43 = 1862.6/s Avg: 21 Min: 0 Max: 5751 Err: 0 (0.00%) summary + 71900 in 00:00:30 = 2394.5/s Avg: 748 Min: 0 Max: 13050 Err: 13551 (18.85%) Active: 35419 Started: 51558 Finished: 16181 summary = 486607 in 00:04:13 = 1925.8/s Avg: 128 Min: 0 Max: 13050 Err: 13551 (2.78%) summary + 57300 in 00:00:30 = 1910.9/s Avg: 0 Min: 0 Max: 129 Err: 54645 (95.37%) Active: 24622 Started: 51558 Finished: 26978 summary = 543907 in 00:04:43 = 1924.2/s Avg: 115 Min: 0 Max: 13050 Err: 68196 (12.54%) summary + 41400 in 00:00:30 = 1378.4/s Avg: 0 Min: 0 Max: 87 Err: 41400 (100.00%) Active: 14119 Started: 51558 Finished: 37481 summary = 585307 in 00:05:13 = 1871.8/s Avg: 106 Min: 0 Max: 13050 Err: 109596 (18.72%) summary + 25000 in 00:00:31 = 816.4/s Avg: 0 Min: 0 Max: 1 Err: 25000 (100.00%) Active: 4577 Started: 51558 Finished: 47023 summary = 610307 in 00:05:43 = 1777.7/s Avg: 102 Min: 0 Max: 13050 Err: 134596 (22.05%) summary + 7900 in 00:00:30 = 267.2/s Avg: 0 Min: 0 Max: 1 Err: 7900 (100.00%) Active: 397 Started: 51558 Finished: 51203 summary = 618207 in 00:06:13 = 1657.9/s Avg: 101 Min: 0 Max: 13050 Err: 142496 (23.05%) summary + 697 in 00:00:30 = 23.0/s Avg: 0 Min: 0 Max: 1 Err: 697 (100.00%) Active: 4 Started: 51558 Finished: 51596 summary = 618904 in 00:06:43 = 1534.8/s Avg: 101 Min: 0 Max: 13050 Err: 143193 (23.14%) summary + 296 in 00:00:09 = 31.4/s Avg: 0 Min: 0 Max: 1 Err: 296 (100.00%) Active: 0 Started: 51558 Finished: 51600 summary = 619200 in 00:06:53 = 1500.4/s Avg: 101 Min: 0 Max: 13050 Err: 143489 (23.17%) Tidying up remote @ Fri Oct 29 12:30:40 CST 2021 (1635481840041) ... end of run从jmeter报告与go服务监测phone端连接数中,可看出连接都成功了,但保持了几个心跳之后,系统内存告警OOM了,被测服务wssrv被系统kill了:
Oct 29 12:27:56 VM-0-14-centos kernel: [ pid ] uid tgid total_vm rss nr_ptes swapents oom_score_adj name Oct 29 12:27:56 VM-0-14-centos kernel: [ 4787] 0 4787 31596 164 19 0 0 crond Oct 29 12:27:56 VM-0-14-centos kernel: [12406] 0 12406 39215 403 79 0 0 sshd Oct 29 12:27:56 VM-0-14-centos kernel: [12420] 0 12420 29149 362 14 0 0 bash Oct 29 12:27:56 VM-0-14-centos kernel: [ 2928] 0 2928 977055 808416 1597 0 0 wssrv Oct 29 12:27:56 VM-0-14-centos kernel: Out of memory: Kill process 2928 (wssrv) score 809 or sacrifice child Oct 29 12:27:56 VM-0-14-centos kernel: Killed process 2928 (wssrv), UID 0, total-vm:3908220kB, anon-rss:3233664kB, file-rss:0kB, shmem-rss:0kB这里不关心失败率问题,因为被测服务被kill了。
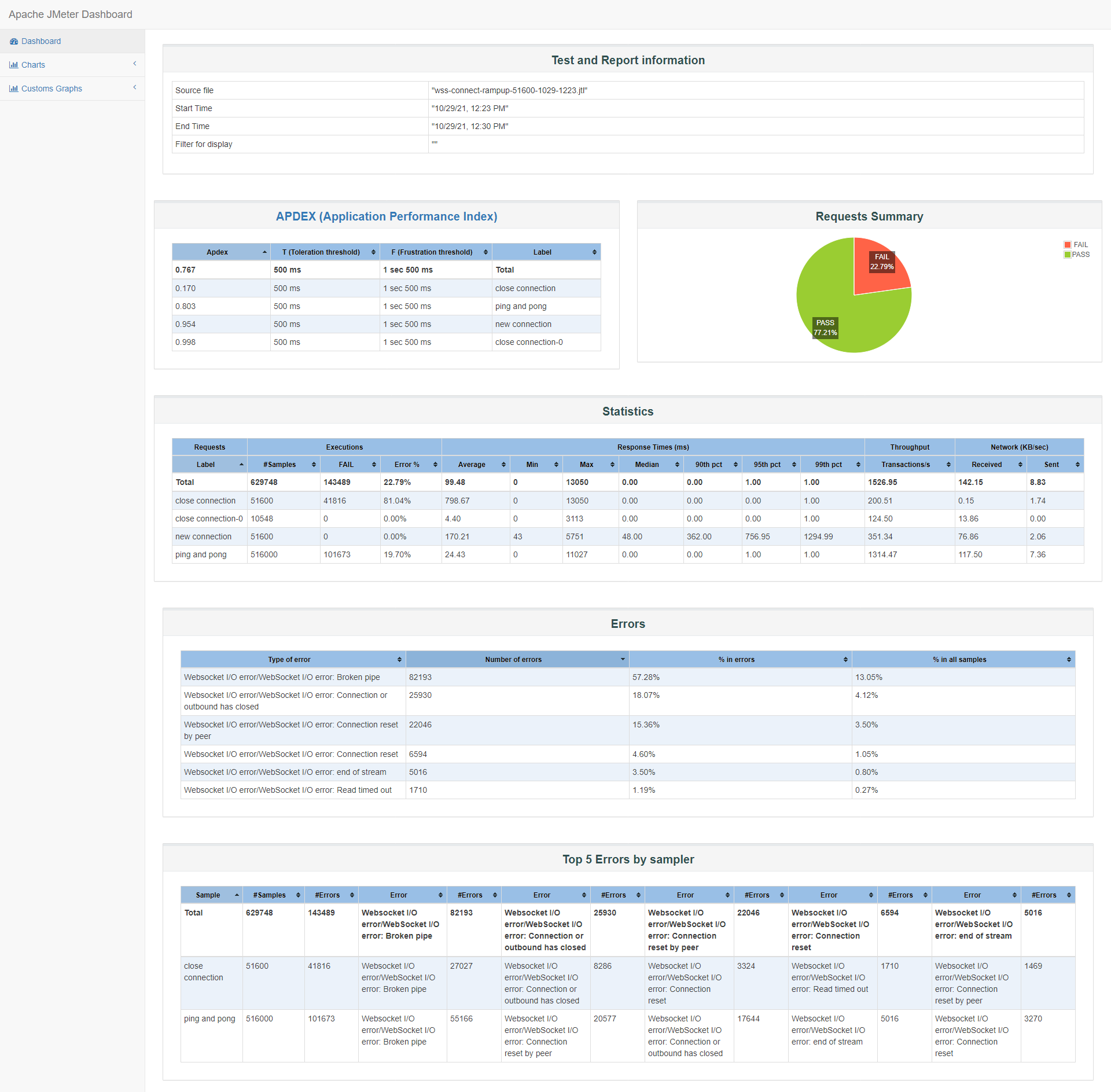
在发起连接期间,也就是前150s,负载依然是很快来到3.5左右,用户态CPU使用率0.66,但在保持了几个心跳后,在12:27分,内存不足,iowait CPU使用率从0突然上涨到0.56,同时负载也上升到5.78,之后被测服务被kill后,释放内存自动重启。
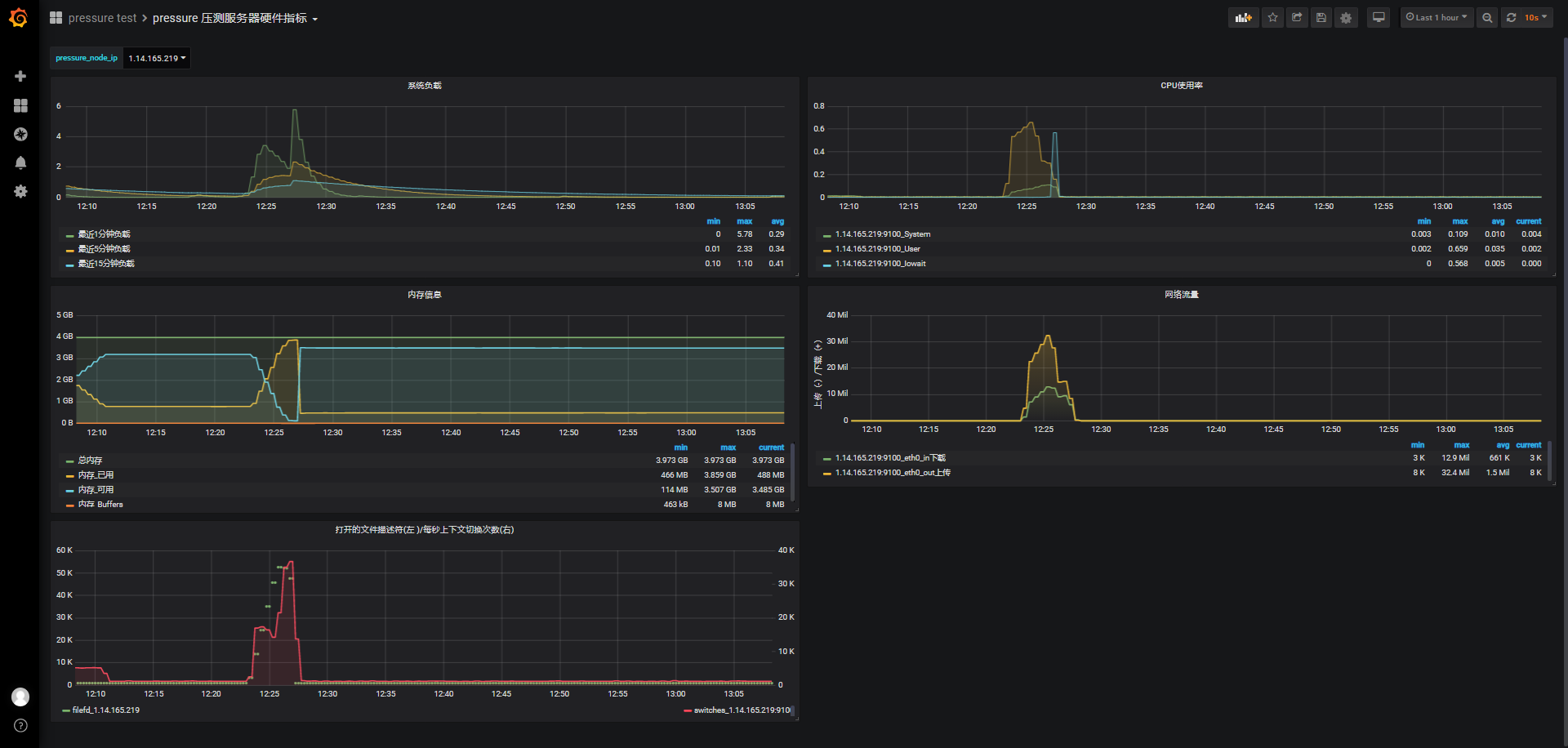
小结:
| item | 数据 |
|---|---|
| 可支持最大wss连接数 | 5w - 5.2w |
| 最大负载 | 3.5 |
| 最高CPU使用率 | 0.66(user),0.1(system) |
| 最大使用内存 | 3.449G,但OOM了 |
| 每个连接消耗内存 | 65K-70K |
模拟web端控制phone端
这个场景,是阶梯连接压测,目的了解web、phone端同时保持连接且交互控制时的最大可连接数。
场景:
30秒(最大150秒)内阶梯性连接所有web端和phone端,维持心跳发送h,客户端心跳时间随机10到30s,维持60次;
web端会在60次心跳中40%的概率发送"let us get together….${__time()}“的消息,也就是每个web端大概会发送24次消息给phone端;
phone端在60次心跳中30%的概率发送"have a nice day….${__time()}“的消息,也就是每个web端大概会发送18次消息给web端;
在60次心跳之后,随机1到10秒关闭对应连接。
web端发送消息给phone端日志确认如下:
[Info] [E:/src/wssrv/phone_web_pair.go 464] [2021-10-27 11:36:45] [id: (b32043e71baf61cea124b0162ba1223a) send to phone=>let us get together....1635305805659]
[Info] [E:/src/wssrv/phone_web_pair.go 464] [2021-10-27 11:36:45] [id: (1e5513456d4272758c4904a38da50e86) send to phone=>let us get together....1635305805658]
[Info] [E:/src/wssrv/phone_web_pair.go 464] [2021-10-27 11:36:45] [id: (c0a32b170c44d1258b66003dde7e33c5) send to phone=>let us get together....1635305805660]
尝试了这些连接数:
-
4w/120s
id:wss-web-phone-40000-1029-1514
20000个web端+20000个phone端
根据之前ws的压测,id:dataforward-web-phone-65800-1027-1133,32900个web端+32900个phone端,在保持连接期间,没有出现OOM。我们先尝试20000个web端+20000个phone端。
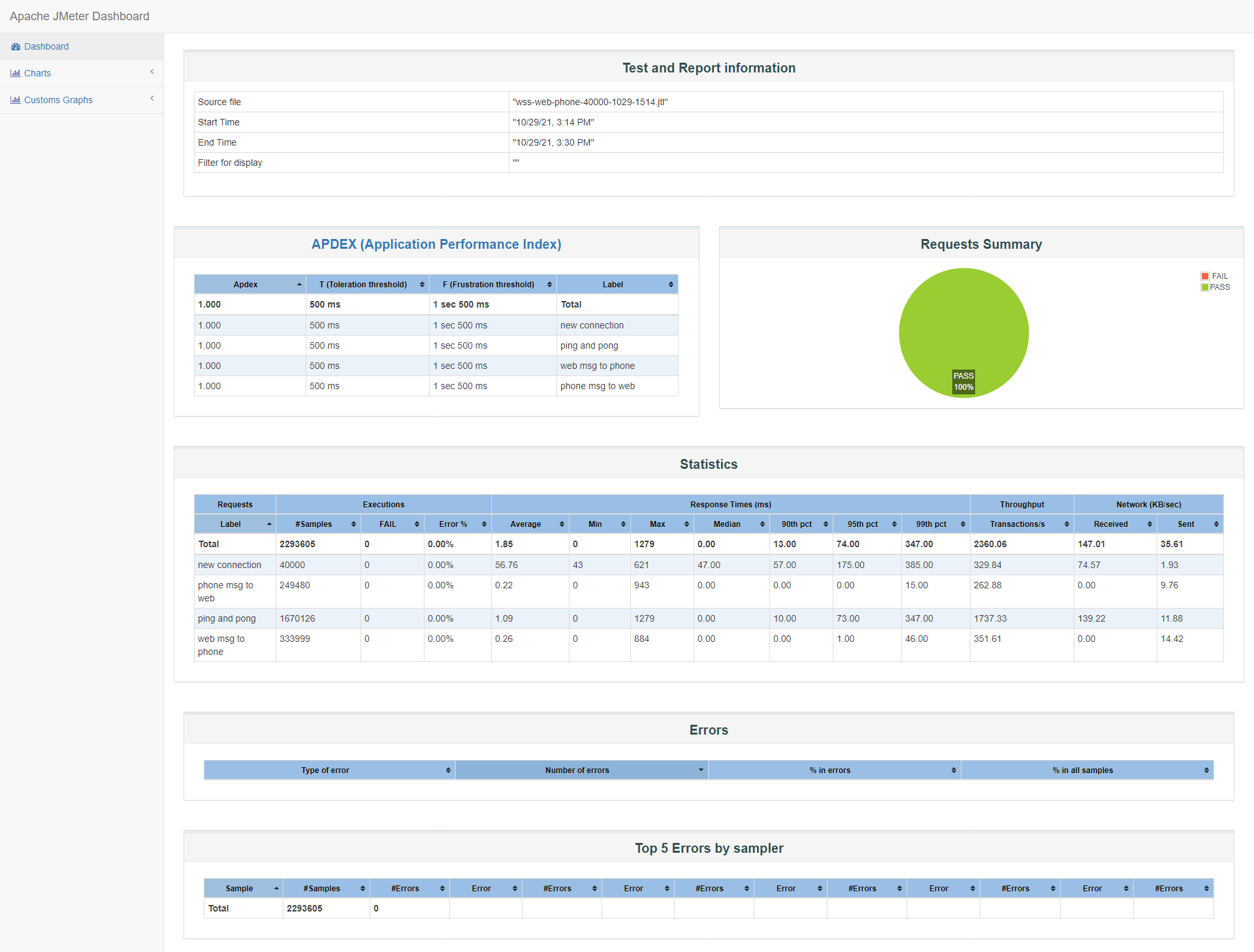
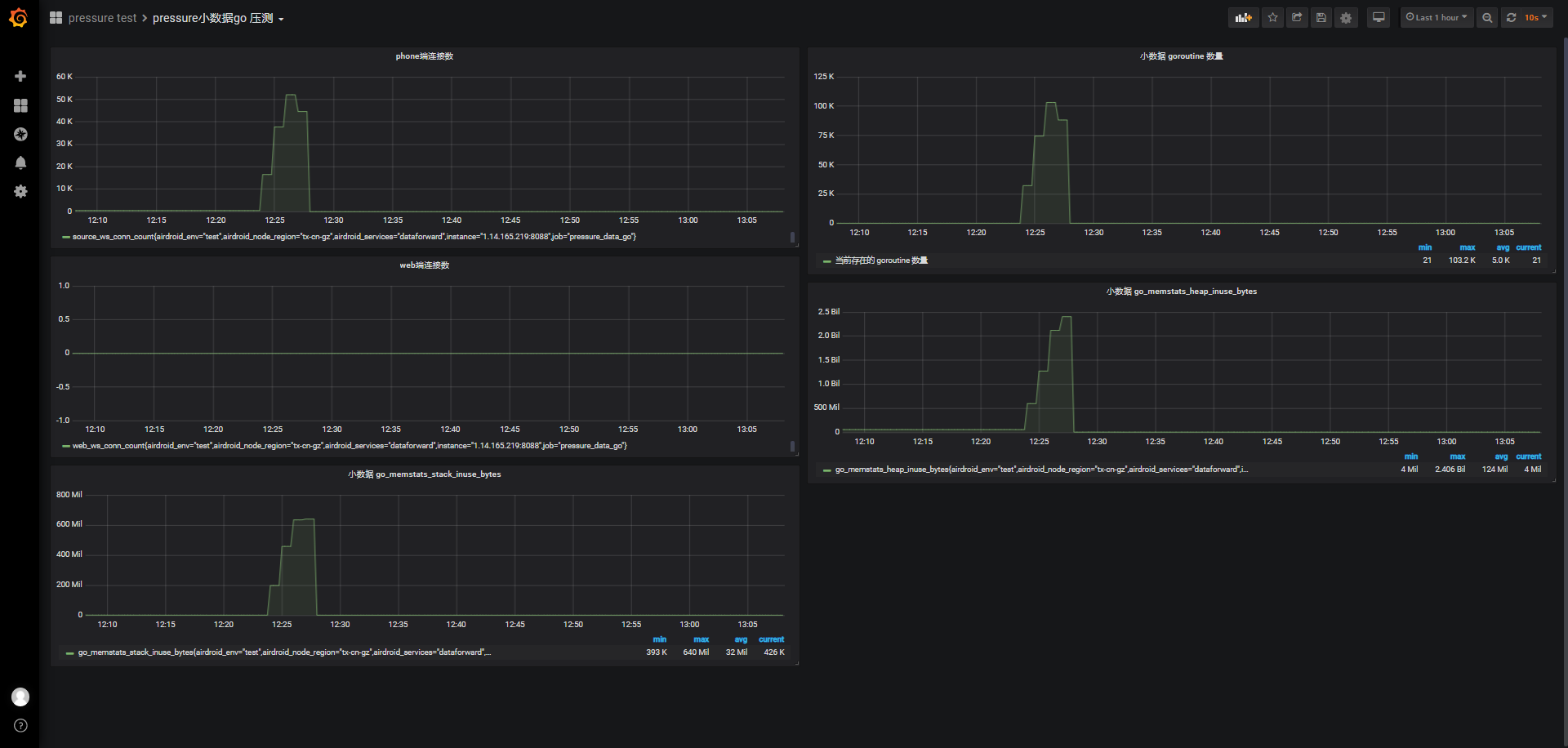
在连接阶段(120s),负载也和单端phone端连接压测一样马上从0上升到2.1左右,用户态CPU使用率也接近0.6,内核CPU使用率整个测试期间不超过0.1,可用内存从3.342G下降到885M,并维持到连接开始关闭(将近维持12分钟),消耗2537M内存,平均一个phone或web端连接消耗65K左右内存(前面有计算过phone端连接也将近消耗68K左右内存)
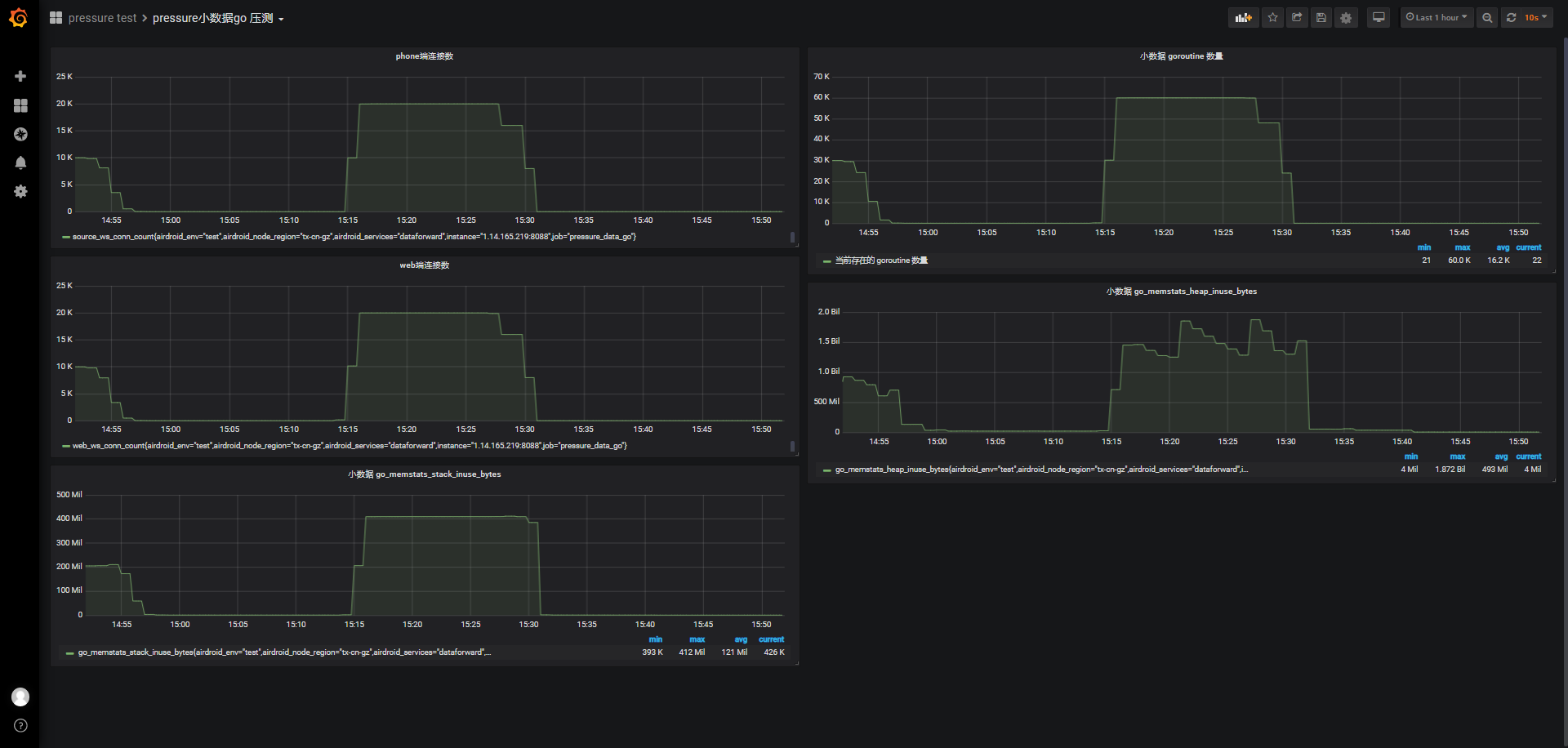
-
5w/150s
id:wss-web-phone-50000-1029-1608
根据上一次4w的测试结果剩余可用内存885M和一对phone和web端消耗约130K内存,理论上服务器还能支持7000对phone和web端的连接,也就是1.4w的连接,但鉴于wss下phone单端最大可连接数测试结果5w-5.2w,我们考虑5w连接,也就是2.5w对phone与web端连接。
由于jmeter客户端内存原因,实际上只提供49980个连接,24990对phone与web端。
负载最高在2.6,维持心跳保活期间负载在1上下波动,之后逐步下降,cpu使用最高在0.56,之后趋于平缓在0.25左右,偏差0.02,可用内存从3.474G下降到260M,并维持到连接开始关闭(将近维持15分钟),消耗3297M内存。
从16:11维持心跳到16:25(大约40次心跳),之后部分jmeter压力机客户端因为机器内存原因被迫kill(不是被测服务wssrv被kill),但在维持心跳期间,服务器内存稳定,可用内存稳定在260M,偏差在10M以内。
ubuntu@VM-1-10-ubuntu:~/jmeter$ jmeter-server -Djava.rmi.server.hostname=172.16.0.16 Created remote object: UnicastServerRef2 [liveRef: [endpoint:[172.16.0.16:44991](local),objID:[-44fee87a:17ccb015468:-7fff, 6430912965959146299]]] Starting the test on host 172.16.0.16:1099 @ Fri Oct 29 16:08:15 CST 2021 (1635494895573) Killed ubuntu@VM-1-10-ubuntu:~/jmeter$ date Fri 29 Oct 2021 04:27:12 PM CST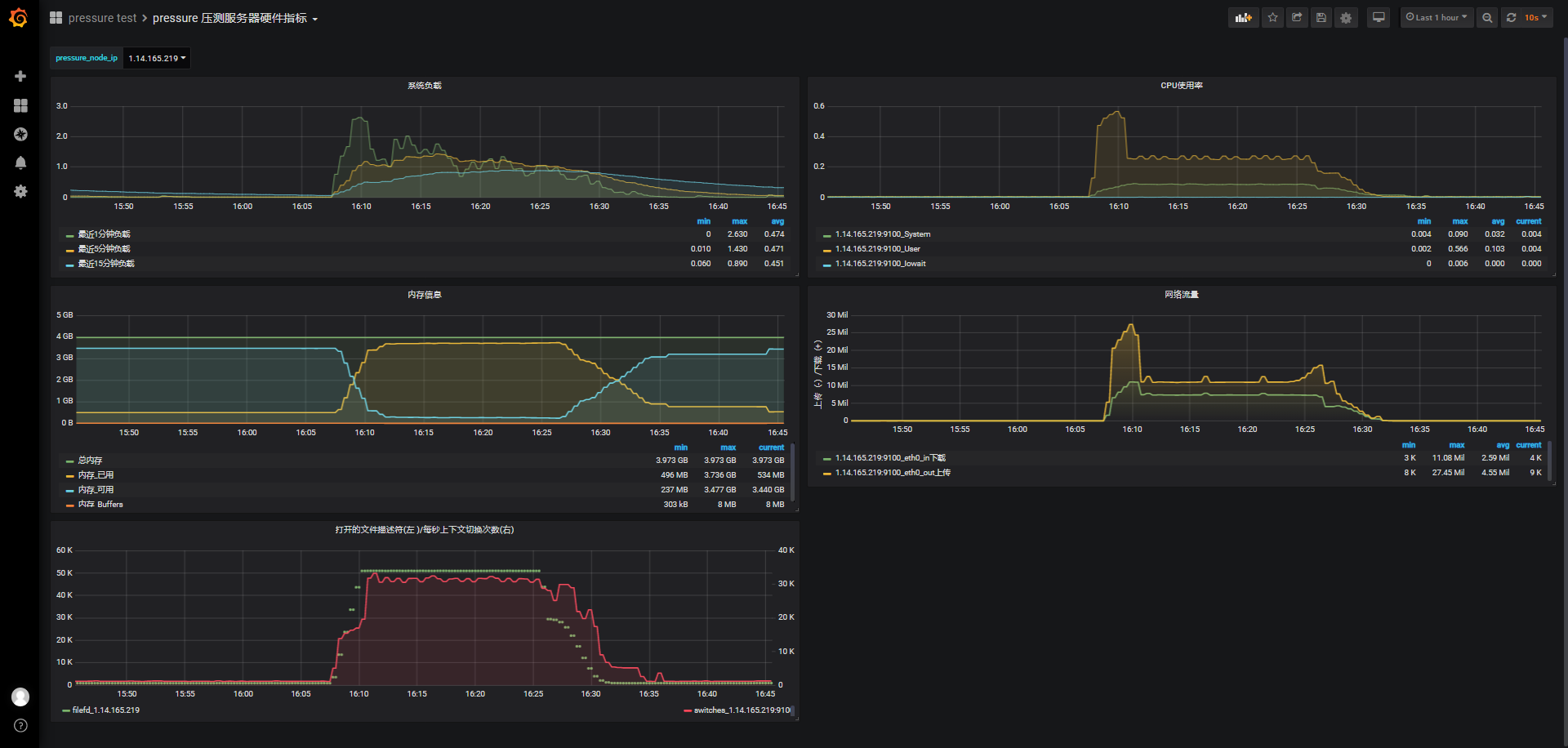
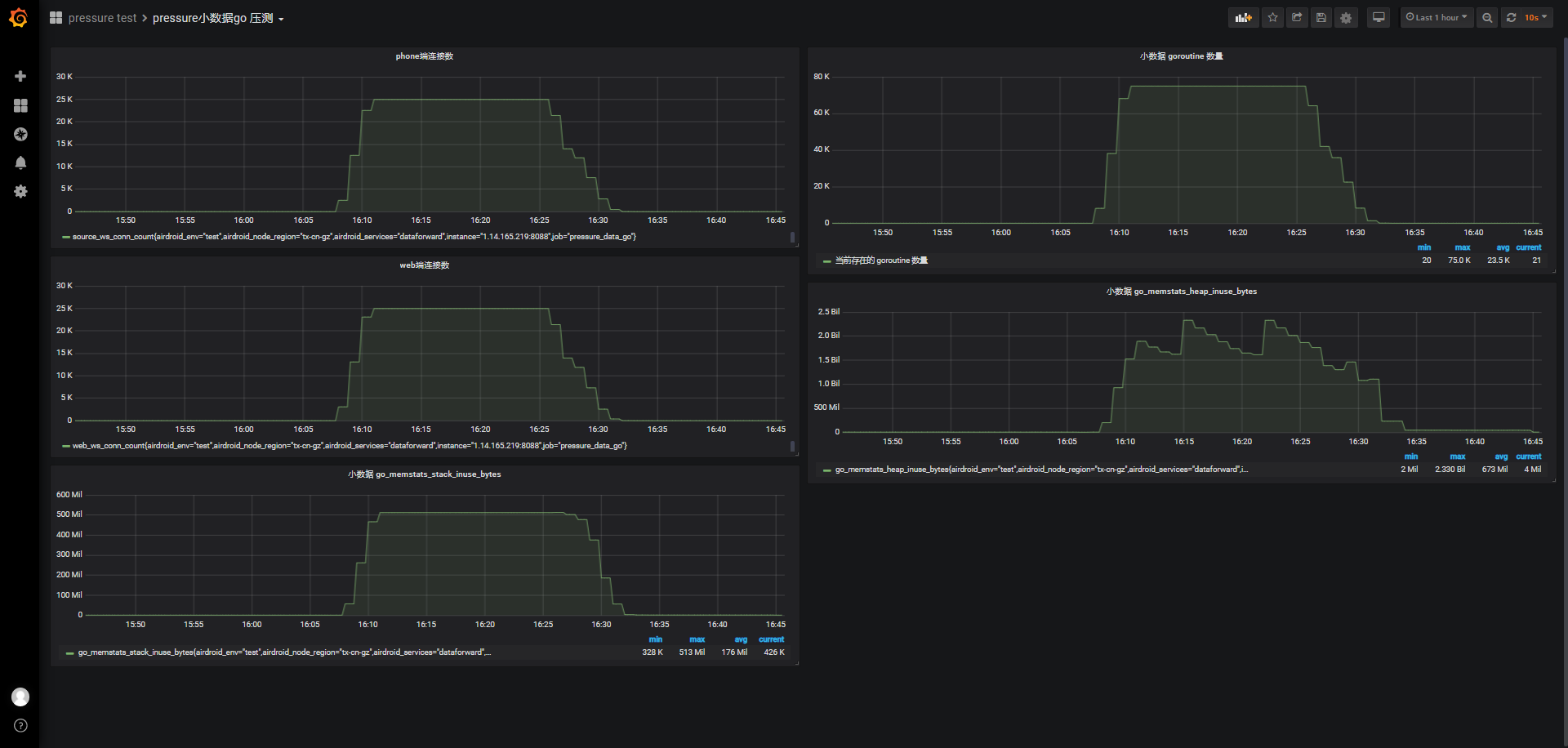
最后,重启被测服务wssrv,系统已使用内存从771M下降到535M,服务本身消耗内存236M,与之前阶梯连接5w/150s的测试结果接近,需要进一步了解这块内存是随着连接数一直上涨还是稳定的?@todo
由于需要比对的是wss直连与nginx转发wss,不再进一步压测。
小结:
2核4G服务器目前可以支持2.5w个web端与2.5w个phone端同时连接wss,并维持至少40次心跳(为了缩短压测时间,每次心跳随机在10~30秒之间,正式心跳时长是2分钟/5分钟),web端随机发送24次消息给phone端。
因为jmeter压力机客户端内存不够的原因,原来需要至少维持60次心跳,这次测试只维持40次左右,但根据被测服务器的监测数据看,没有太大影响。
方式二、通过nginx转发wss
并发连接
场景:
phone端并发连接,瞬间并发,每30秒发一次心跳,维持3次后,1至5s后关闭。
希望找出可最大并发连接数。
尝试了这些并发量:
基于wss直连的测试结果,从2500并发开始:
-
2500
并发了一组,发现响应速度/满意度比之前wss直连的方式高,所以又针对wss直连方式重新做了2组2500的并发,看起来比之前好点,但改善不多,而nginx+wss的并发也多做了几组,贴上一些数据比对:
id:wss-connect-nginx-2500-1029-1740
实现方式 并发数 samples failed error median 90th pct TPS Apdex 2500 wss直连 2500 37 1.48% 4170.00 7790.00 239.39 0.137 2500 wss直连 2500 0 0.00% 1927.50 7420.00 308.26 0.253 2500 wss直连 2500 38 1.52% 1539.00 8047.00 236.07 0.348 2500 nginx+wss 2500 0 0.00% 101.00 4594.00 268.50 0.777 2500 nginx+wss 2500 0 0.00% 1170.00 3227.00 318.59 0.575 再看wss直连与nginx+wss,分别最近一次的服务器监测比对:(17:33是wss直连2500并发,17:41是nginx+wss并发2500)
wss直连负载、cpu都会高于nginx+wss,但都属于低负载、低使用率:
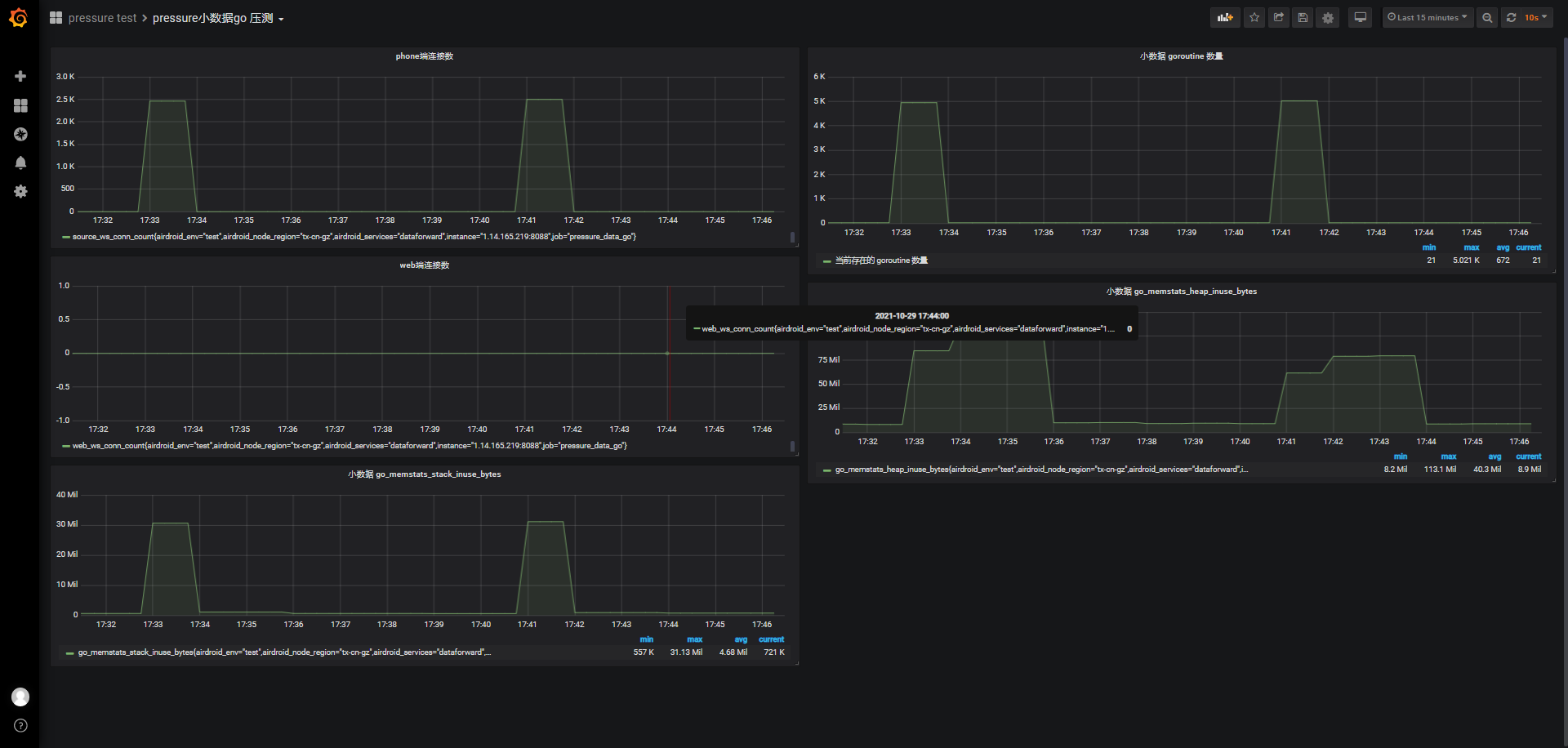
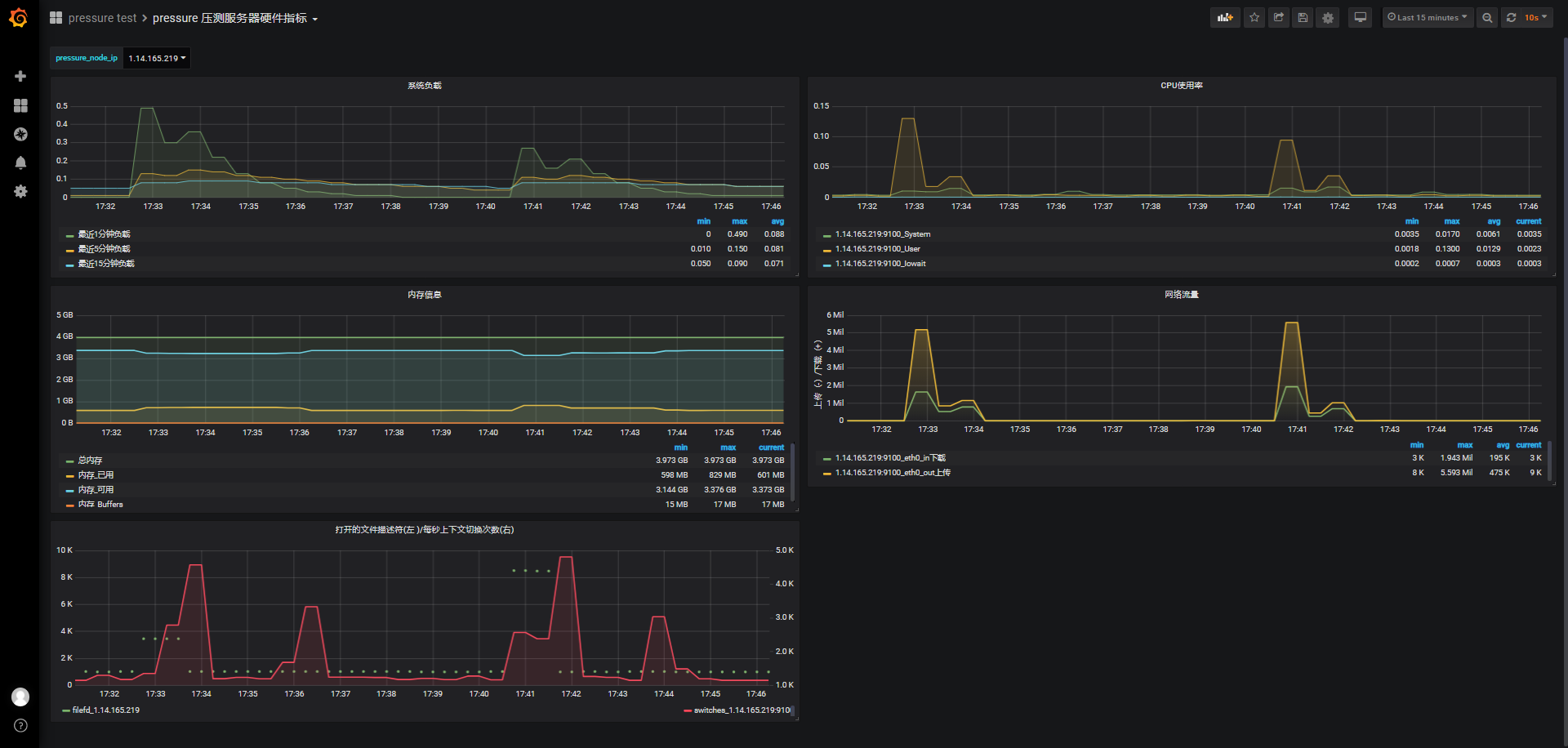
-
2000
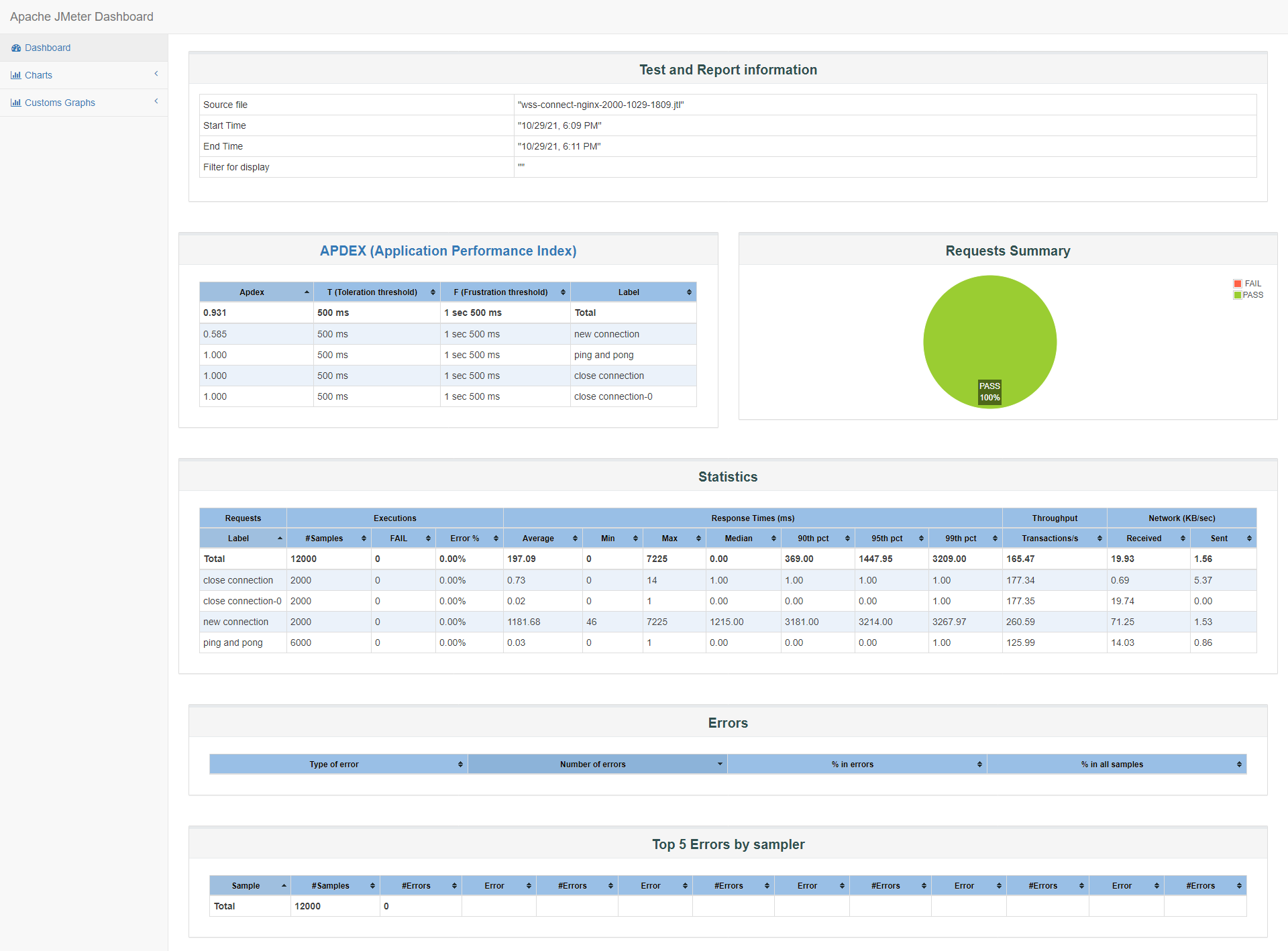
id:wss-connect-nginx-2000-1029-1809
实现方式 并发数 samples failed error median 90th pct TPS Apdex 2000 wss直连 2000 0 0.00% 1669.00 7452.90 249.69 0.234 2000 nginx+wss 2000 0 0.00% 1100.00 3132.00 504.92 0.639 2000 nginx+wss 2000 0 0.00% 1215.00 3181.00 260.59 0.585 详见jmeter 报告概览:
服务器负载、cpu使用率、内存使用情况,都和wss直连差不多,这里就不再贴,如果有需要查看,可以通过id到grafana管理后台上查看。
-
1500
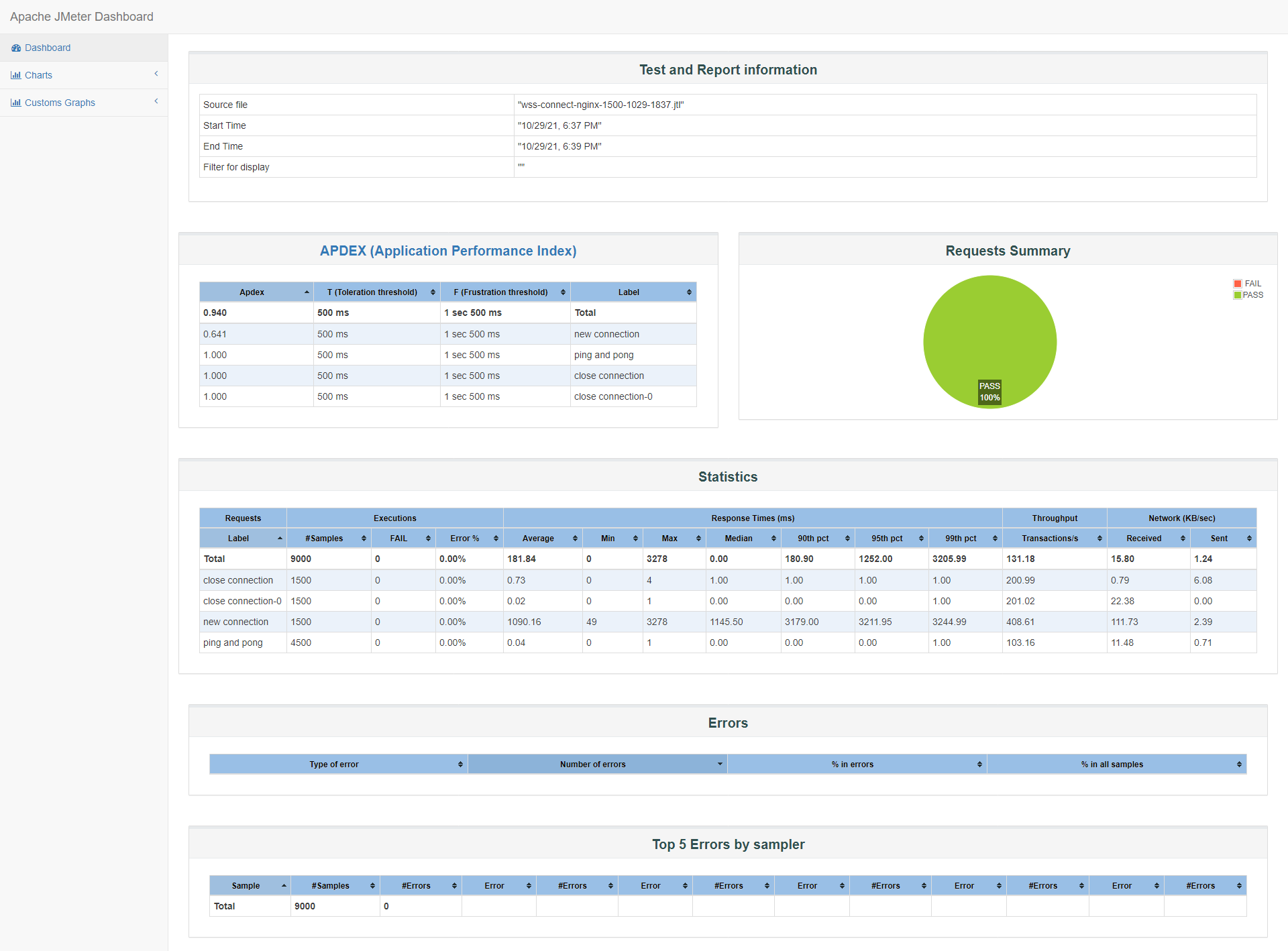
id:wss-connect-nginx-1500-1029-1837
在1500并发下,由于服务器资源完全充足,这里不贴服务器监测数据,如果有需要可以参考id到grafana上查看比对,客户端响应时间、TPS比wss直连方式略微提高,Apdex满意指数从0.328(wss直连)提升到0.641(nginx+wss)。
小结里,我们会在表格里放相关wss直连与nginx+wss的方式相同并发数的结果比对。
-
1000
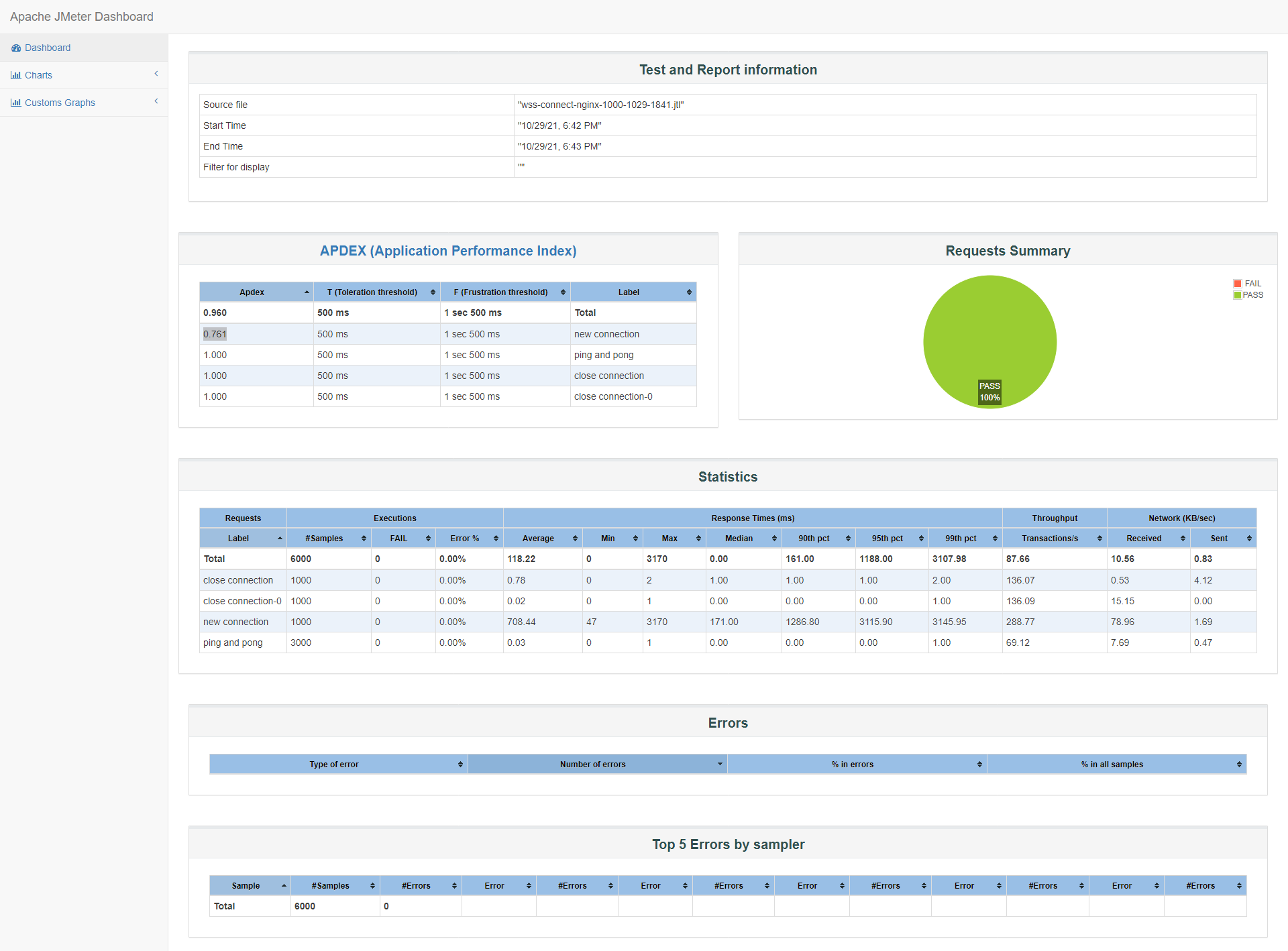
id:wss-connect-nginx-1000-1029-1841
从图中可以了解到90%的客户响应时间已经在1286ms以下,中位数50%的客户端响应时间在171ms,比之前wss直连的1000并发结果提升了2~10倍,满意度也翻倍到0.761:
-
800
id:wss-connect-nginx-800-1029-1846
继续梯度下降寻找满意度0.9以上的并发,也就是90%的客户端响应时间在500ms以下,在800并发比1000并发略微提升,没有明显变化,详见小结表格。
-
600
id:wss-connect-nginx-600-1029-1850
Apdex满意度0.870,接近0.9,90%客户端响应时间还在1000ms外(1128ms)
-
500
id:wss-connect-nginx-400-1031-0918
-
400
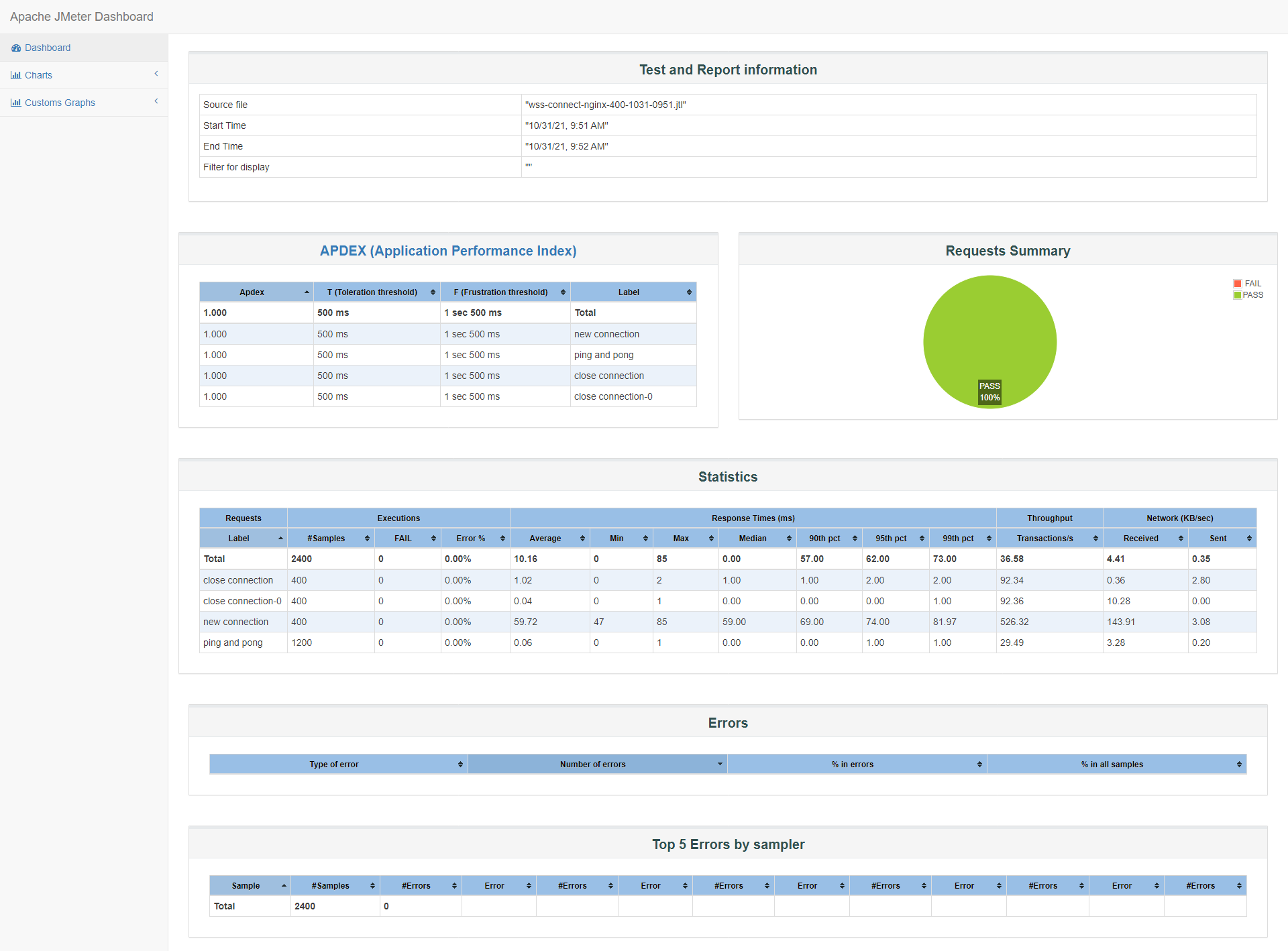
id:wss-connect-nginx-400-1031-0918
为了确认数据真实可靠,我们对这组400并发做了至少4组测试,贴上最后一组报告,可以看到90%的客户端响应时间在69ms,甚至99%的响应时间在100ms以下,满意度1.0,在小结表格里贴上最后两组数据:
-
1500/ssl_session_cache
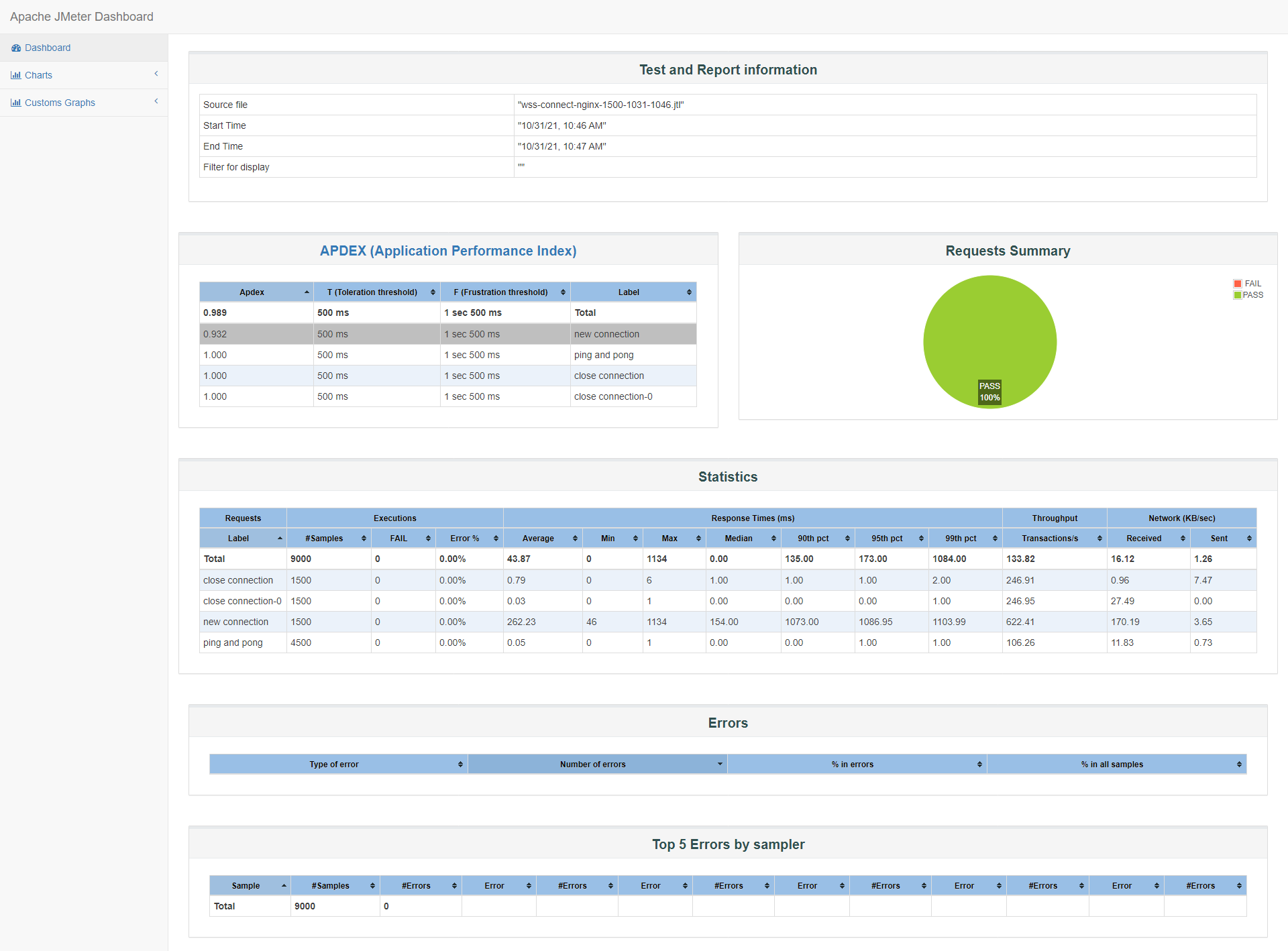
由于使用到nginx转发,nginx在TLS配置方面也提供了一些优化配置,详见优化章节,我们针对ssl_session_cache做一组比对测试,了解ssl_session_cache在这方面是否也起到比较大的影响。
#nginx ssl ssl_session_cache shared:SSL:10m; ssl_session_timeout 1h;90%的响应时间在1073ms以下,满意度达到0.932。
结果和之前只设置ssl_session_timeout,而没有设置ssl_session_cache的1500并发比对,详见小结。
-
400/外网
这里的外网的意思是不通过局域网访问服务,外网的压测,网络状况对测试结果影响较大,且难以模拟真实用户网络状况,而且,这次测试主要是监测对比wss直连与nginx+wss两种方式,所以这里也暂时不做太多外网压测,ws协议的压测有做过几组外网测试,可以参考:wssrv-ws协议-压测报告
回头来补充了外网几组测试:
50%与90%的客户端响应时间都在2500ms下,且max也才2549ms,平均2118ms,看起来连接响应时间很平均,但TPS比较低只有124,满意度Apdex为0.1,确认了大部分连接的响应时间不在500ms以下,不快,但都在3s以内:
id:wss-connect-ext-400-1101-1119
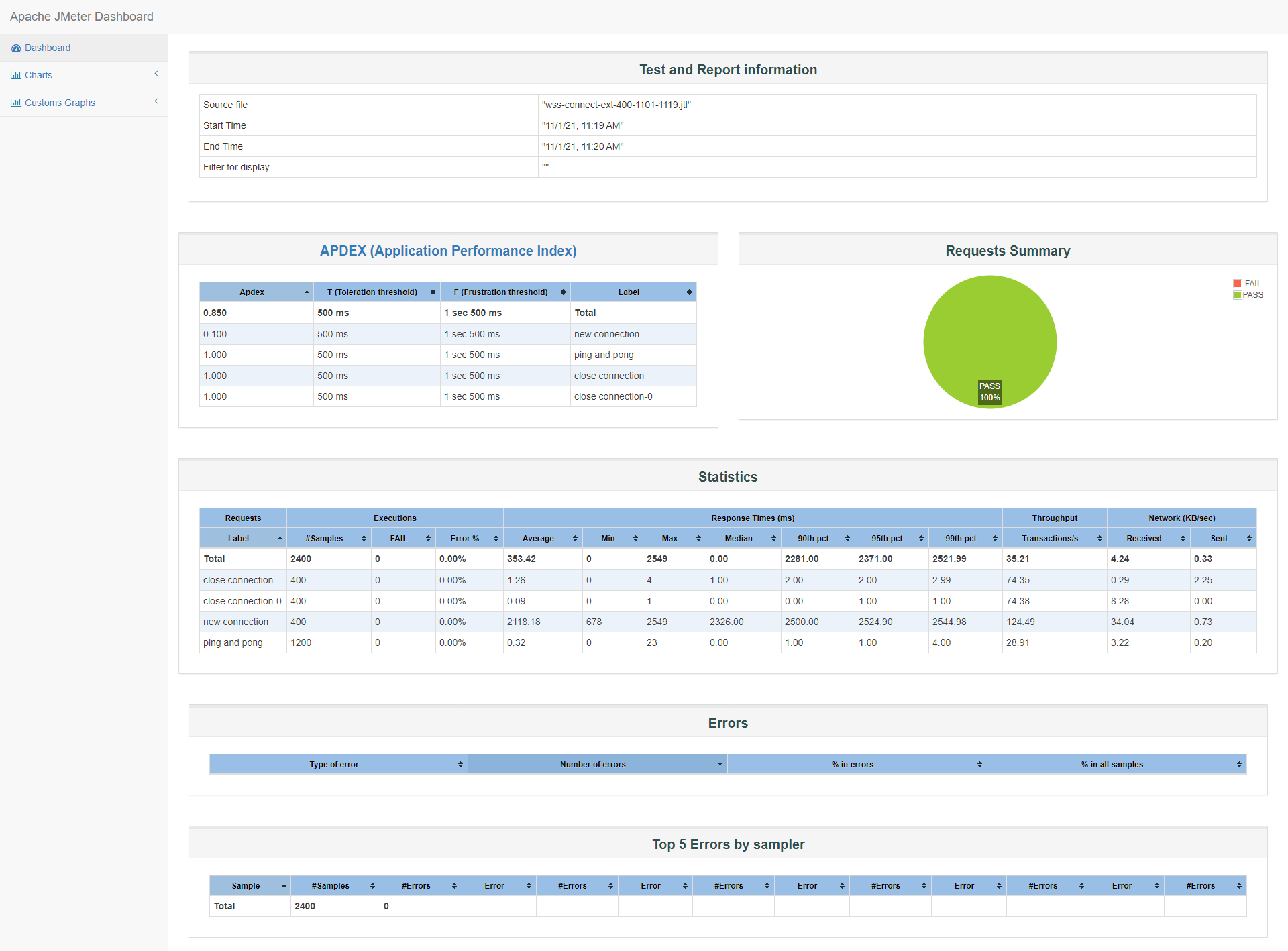
服务器资源情况没有太突出:
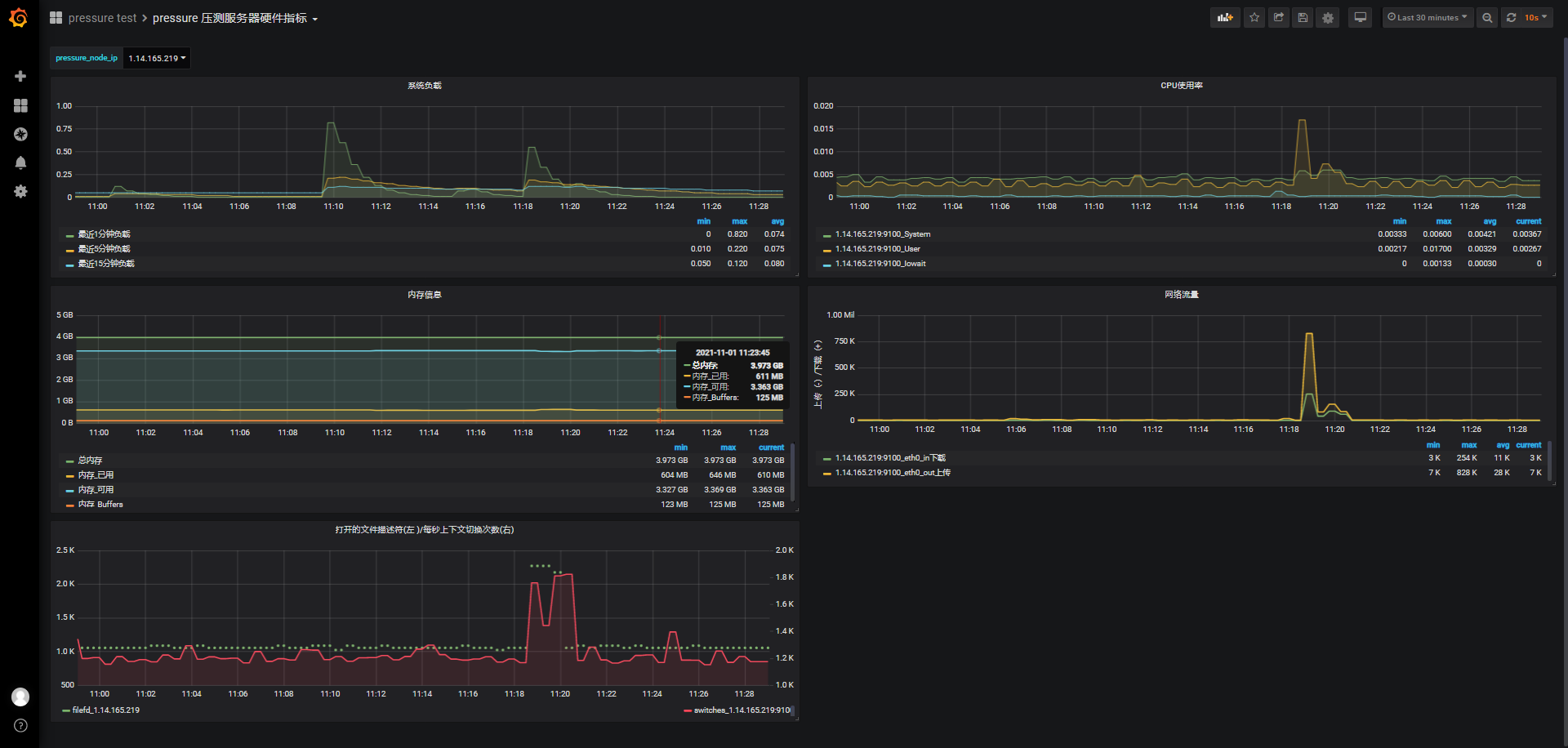
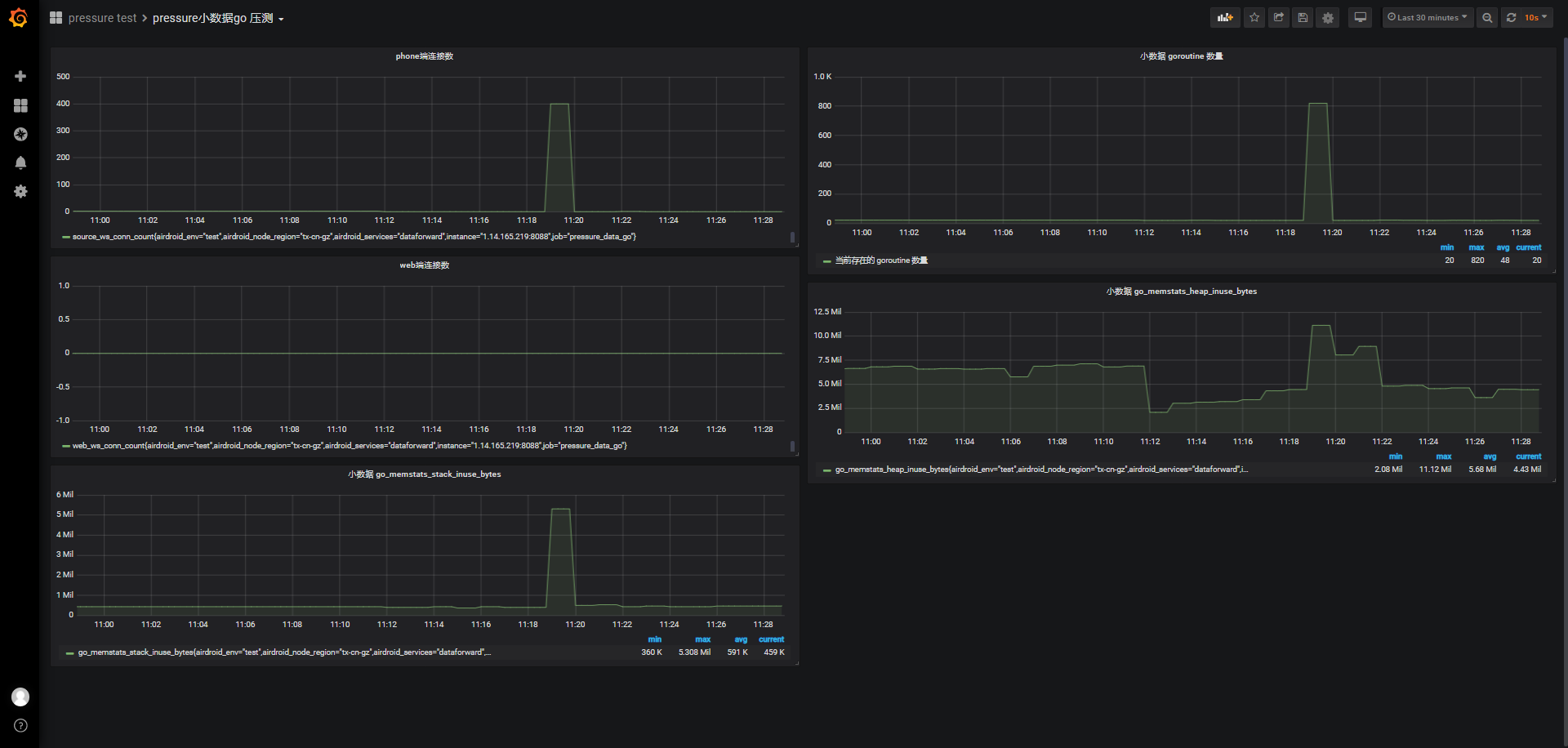
小结:
以下表格中按并发数降序排列,每组并发量一样或相近都有wss直连和nginx+wss两种方式的比对,最后我们对nginx的部分TLS方面的配置简单修改后,做了两组1500并发的测试,主要是验证nginx在session方面对连接的优化提升效果,其他更多优化需要后续更多比对测试:
| 并发数 | 实现方式 | samples | failed | error | median | 90th pct | TPS | Apdex |
|---|---|---|---|---|---|---|---|---|
| 2500 | wss直连 | 2500 | 37 | 1.48% | 4170.00 | 7790.00 | 239.39 | 0.137 |
| 2500 | wss直连 | 2500 | 0 | 0.00% | 1927.50 | 7420.00 | 308.26 | 0.253 |
| 2500 | wss直连 | 2500 | 38 | 1.52% | 1539.00 | 8047.00 | 236.07 | 0.348 |
| 2500 | nginx+wss | 2500 | 0 | 0.00% | 101.00 | 4594.00 | 268.50 | 0.777 |
| 2500 | nginx+wss | 2500 | 0 | 0.00% | 1170.00 | 3227.00 | 318.59 | 0.575 |
| 2000 | wss直连 | 2000 | 0 | 0.00% | 1669.00 | 7452.90 | 249.69 | 0.234 |
| 2000 | nginx+wss | 2000 | 0 | 0.00% | 1100.00 | 3132.00 | 504.92 | 0.639 |
| 2000 | nginx+wss | 2000 | 0 | 0.00% | 1215.00 | 3181.00 | 260.59 | 0.585 |
| 1500 | wss直连 | 1500 | 0 | 0.00% | 1229.50 | 3440.00 | 388.20 | 0.328 |
| 1500 | nginx+wss | 1500 | 0 | 0.00% | 1145.50 | 3179.00 | 408.61 | 0.641 |
| 1000 | wss直连 | 1000 | 0 | 0.00% | 1648.00 | 3369.90 | 277.70 | 0.357 |
| 1000 | nginx+wss | 1000 | 0 | 0.00% | 171.00 | 1286.80 | 288.77 | 0.761 |
| 800 | nginx+wss | 800 | 0 | 0.00% | 164.00 | 1231.90 | 236.41 | 0.789 |
| 750 | wss直连 | 750 | 0 | 0.00% | 545.00 | 1558.90 | 223.48 | 0.528 |
| 500 | wss直连 | 500 | 0 | 0.00% | 310.00 | 1310.90 | 335.12 | 0.809 |
| 500 | nginx+wss | 500 | 0 | 0.00% | 137.00 | 1099.90 | 335.12 | .910 |
| 400 | wss直连 | 400 | 0 | 0.00% | 304.50 | 1146.00 | 301.20 | 0.879 |
| 400 | nginx+wss | 400 | 0 | 0.00% | 62.00 | 83.90 | 518.13 | 1.0 |
| 400 | nginx+wss | 400 | 0 | 0.00% | 59.00 | 69.00 | 526.32 | 1.0 |
| 1500 | nginx+wss+ssl_session_cache | 1500 | 0 | 0.00% | 154.00 | 1073.00 | 622.41 | 0.932 |
| 1500 | nginx+wss+ssl_session_cache | 1500 | 0 | 0.00% | 164.00 | 1099.00 | 724.99 | 0.860 |
| 400外网 | nginx+wss+ssl_session_cache | 400 | 0 | 0.00% | 2326.00 | 2500.00 | 124 | 0.1 |
在nginx+wss方式下,从上表格可以观察到:从2500并发(尝试了几组有完全成功的,也有1%左右的超时)开始能完成所有并发连接,但满意度很低,也就是90%的客户端响应时间太长,TPS也不高;随着并发梯度下降到1000并发,90%的客户端响应时间才在1500ms以下,直到400并发时,Apdex满意指数达到1(1表示所有用户满意)。
而最后我们又对nginx的tls配置补充了ssl_session_cache设置后,重新压测了1500并发,对比前后两组1500并发,响应时间缩短了3到8倍,TPS也有很明显提升,从400+提升到600+。
所以nginx在tls配置方面可能还有优化空间,暂时不再做更多关于并发的压测,可以先从理论上去调整配置,之后有需要的话,再根据实际配置与推算数据,进行压测确认。优化章节
外网@todo
阶梯连接
场景:
phone端阶梯连接,30秒(最大150秒)内完成所有用户连接,每10~30秒随机心跳,维持10次后,1~10秒关闭.
我们希望找出服务器可支持的最大连接数。
注:本次压测的另一个目的是了解nginx+wss维持连接的稳定性,在最大可连接数方面没有做太多组测试。
尝试了这些连接数量:
-
5w/150s
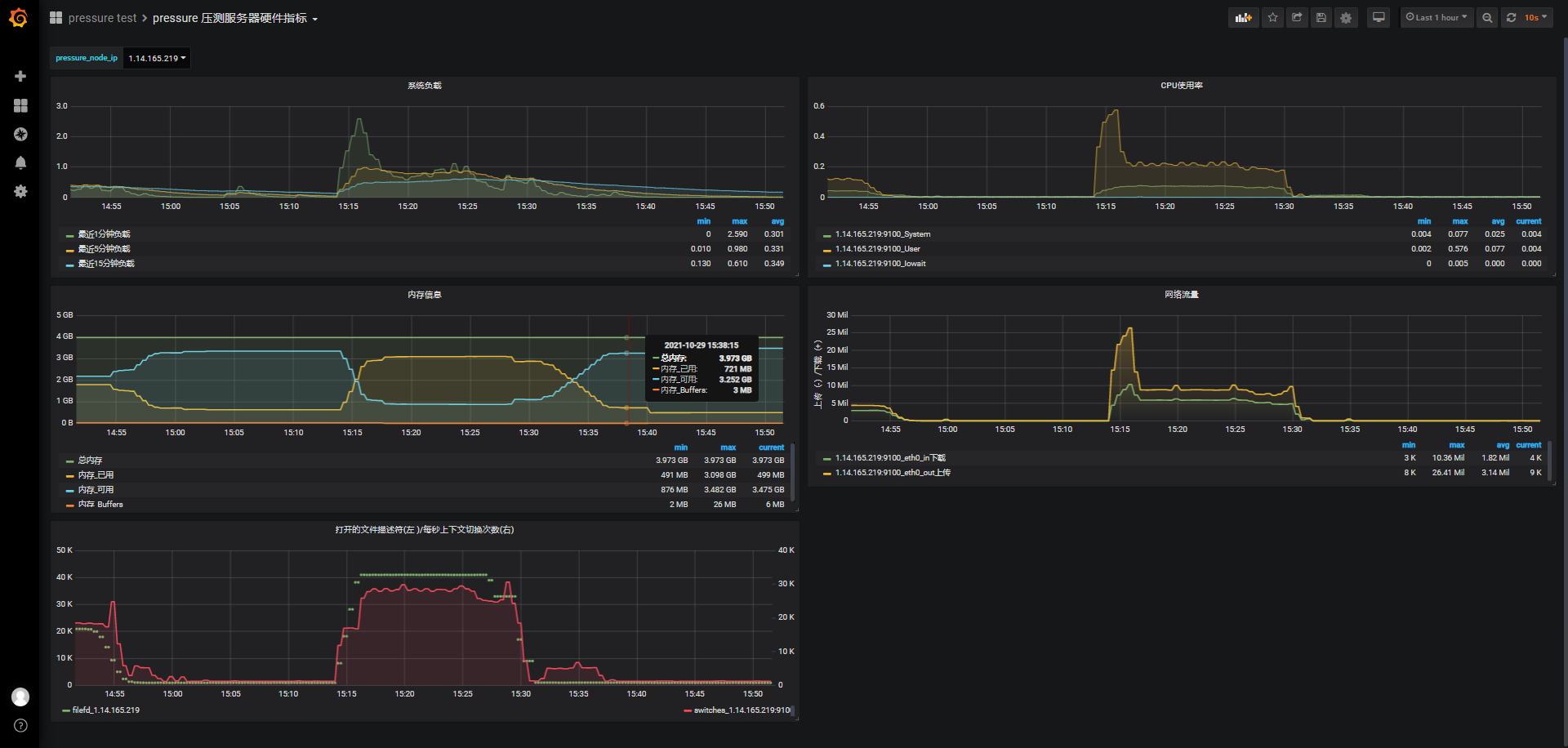
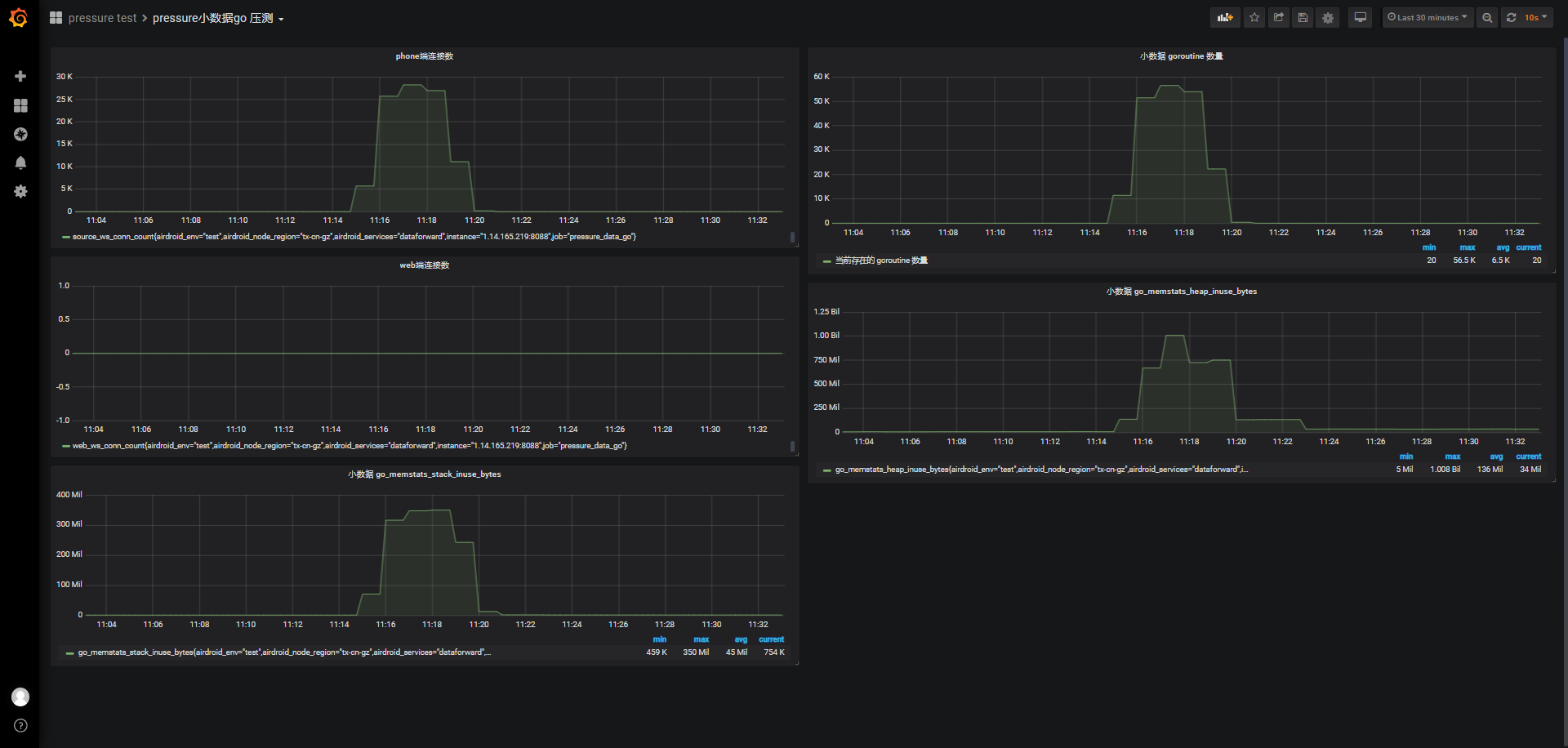
id:wss-connect-rampup-nginx-50000-1031-1115
同样的,不考虑并发,我们在150s内完成5w个连接,从监测图上可以看到期间负载逐渐上升到4.5左右,cpu使用率也很快接近0.8,这个有点出乎意外,甚至我们看报告时有将近40%的超时连接,从小数据go压测监测图上看只有28.23K连接成功,且内存可使用从3.352G下降到最低时的299M,消耗3133M内存;
而之前wss直连内存使用情况:连接前的可用内存3.372G,连接成功并保持连接期间,系统最低可用内存剩余126M,5w连接消耗了3327M内存,结合前面几次内存消耗情况,一个phone端的连接保持大概占用68k左右内存。
显然哪里有问题,初步怀疑是不是因为nginx的什么设置不够大导致连接数受限或超时?
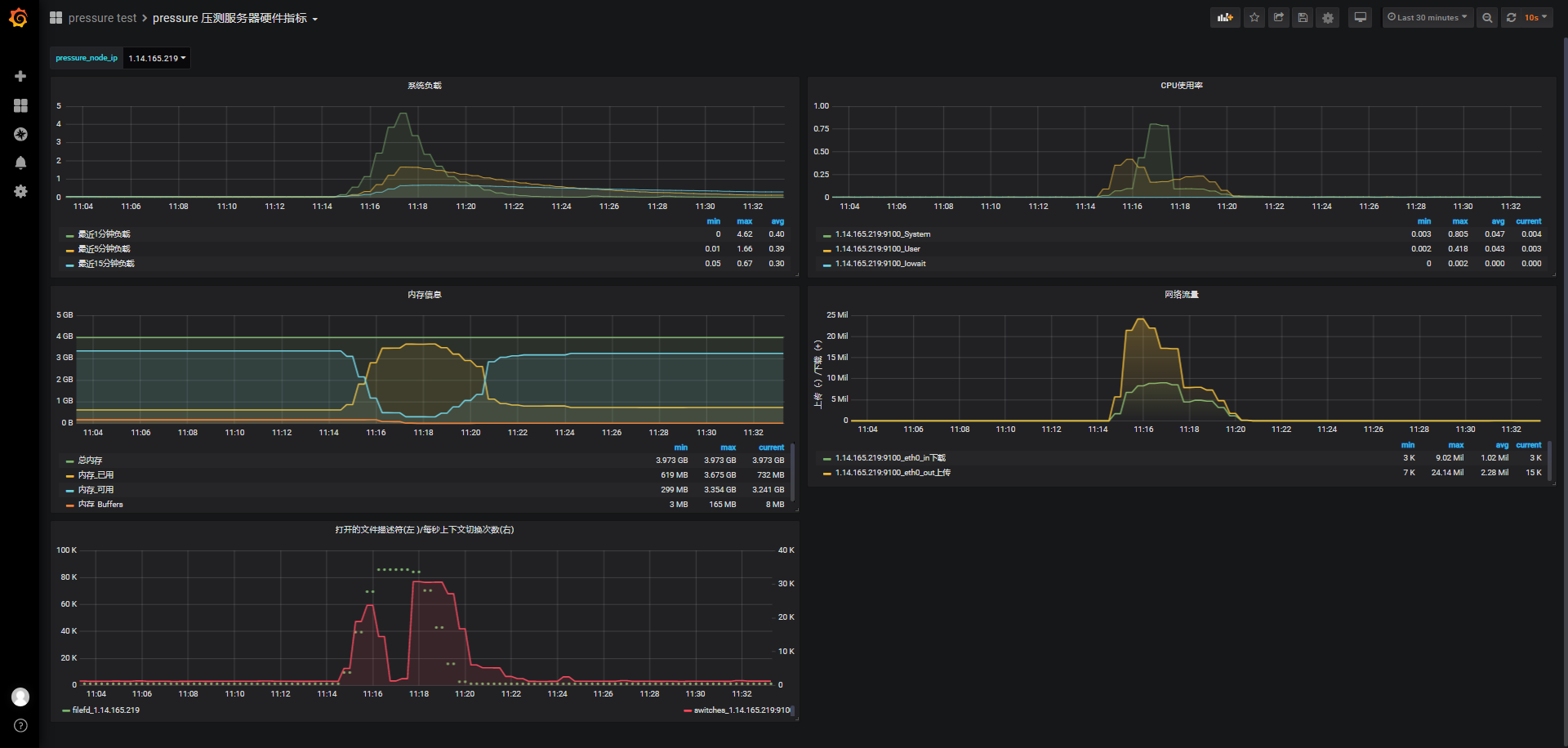
jmeter客户端报告概览:
我们看连接时都发生了什么错误,总共有21764个连接错误:
错误类型 错误数 502/Got unexpected status 502 with statusLine:HTTP/1.1 502 Bad Gateway 10669 Websocket I/O error/WebSocket I/O error: Connect timed out 9661 Websocket I/O error/WebSocket I/O error: Read timed out 1198 Websocket I/O error/WebSocket I/O error: Connection reset 178 Websocket I/O error/WebSocket I/O error: Socket is closed 58 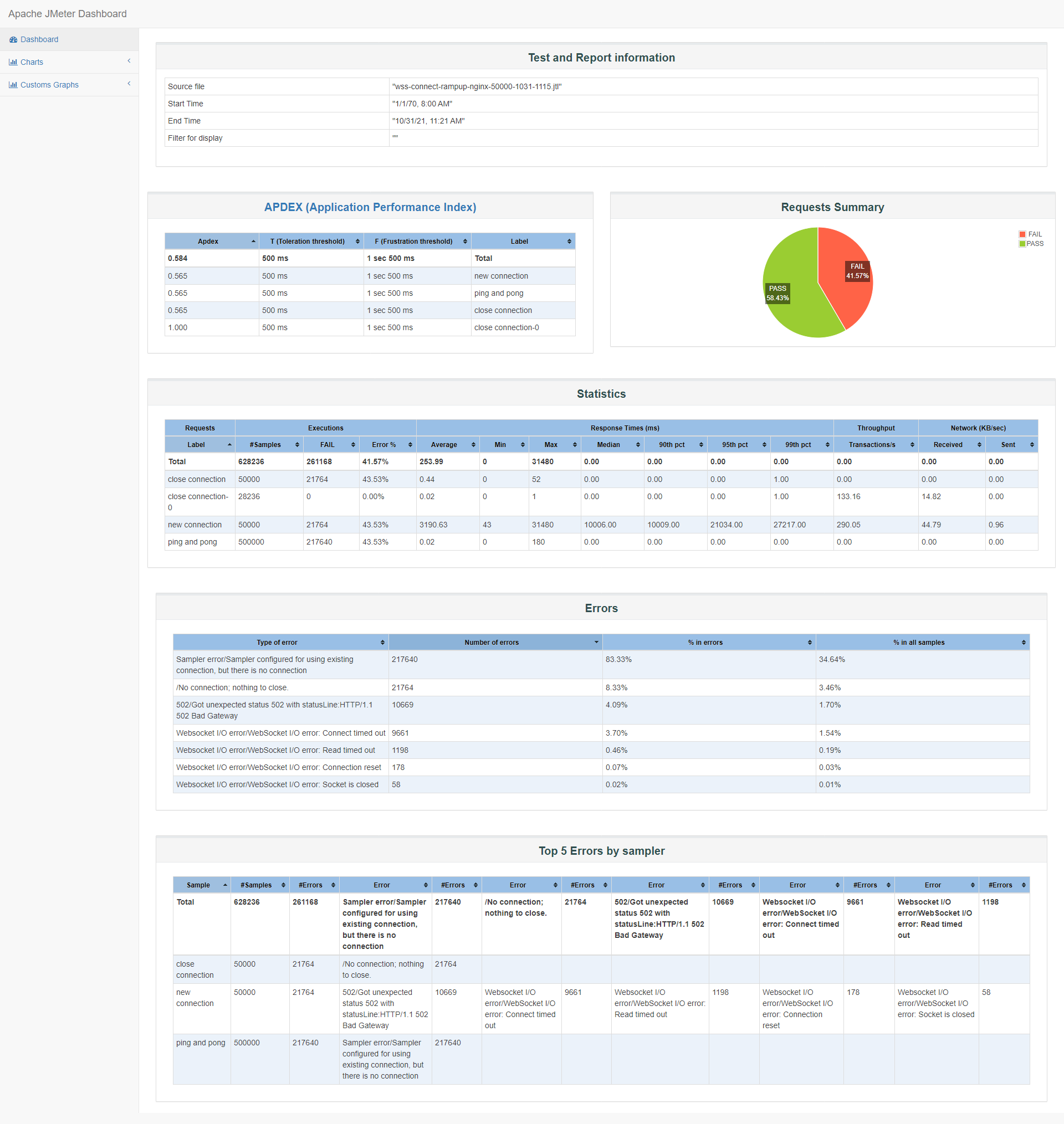
查看了nginx错误日志:
2021/10/31 11:16:45 [crit] 27401#0: *62459 connect() to 127.0.0.1:8088 failed (99: Cannot assign requested address) while connecting to upstream, client: 172.16.0.2, server: test-pressure-data.9ong.com, request: "GET /phone?id=ae8a21d87db61d9de937b597119b5f93&token=7a0746b20bc85e72f55ce097e6de6019&device_type=71&heartbeat=1&instance_id=ae8a21d_db61d9d HTTP/1.1", upstream: "http://127.0.0.1:8088/phone?id=ae8a21d87db61d9de937b597119b5f93&token=7a0746b20bc85e72f55ce097e6de6019&device_type=71&heartbeat=1&instance_id=ae8a21d_db61d9d", host: "test-pressure-data.9ong.com:443" . .出现99: Cannot assign requested address这个错误的原因,是因为nginx作为反向代理时,为了支持长连接,nginx也扮演了websocket服务的客户端角色,nginx需要从本地申请新的端口发起连接到websocket服务,比如我们这次测试的127.0.0.1:8088,而系统分配从local发起请求的端口是有限制的,通常是32768到60999,也就是28232个,刚好和我们前面提到的28.23k个成功连接时相吻合的。(cat /proc/sys/net/ipv4/ip_local_port_range)
所以nginx+wss的方式,受限于ip_local_port_range的限制,会导致最大可连接数下降,而且一台服务器同时最多只能提供不到5w的本地转发本地端口(假设调整了ip_local_port_range),所以这块后续优化可以考虑nginx除了转发角色外还承担LB的角色,需要注意原来逻辑是中心化的,也就是数据不是分布式的,详见优化章节。
-
5w/150 调整端口数
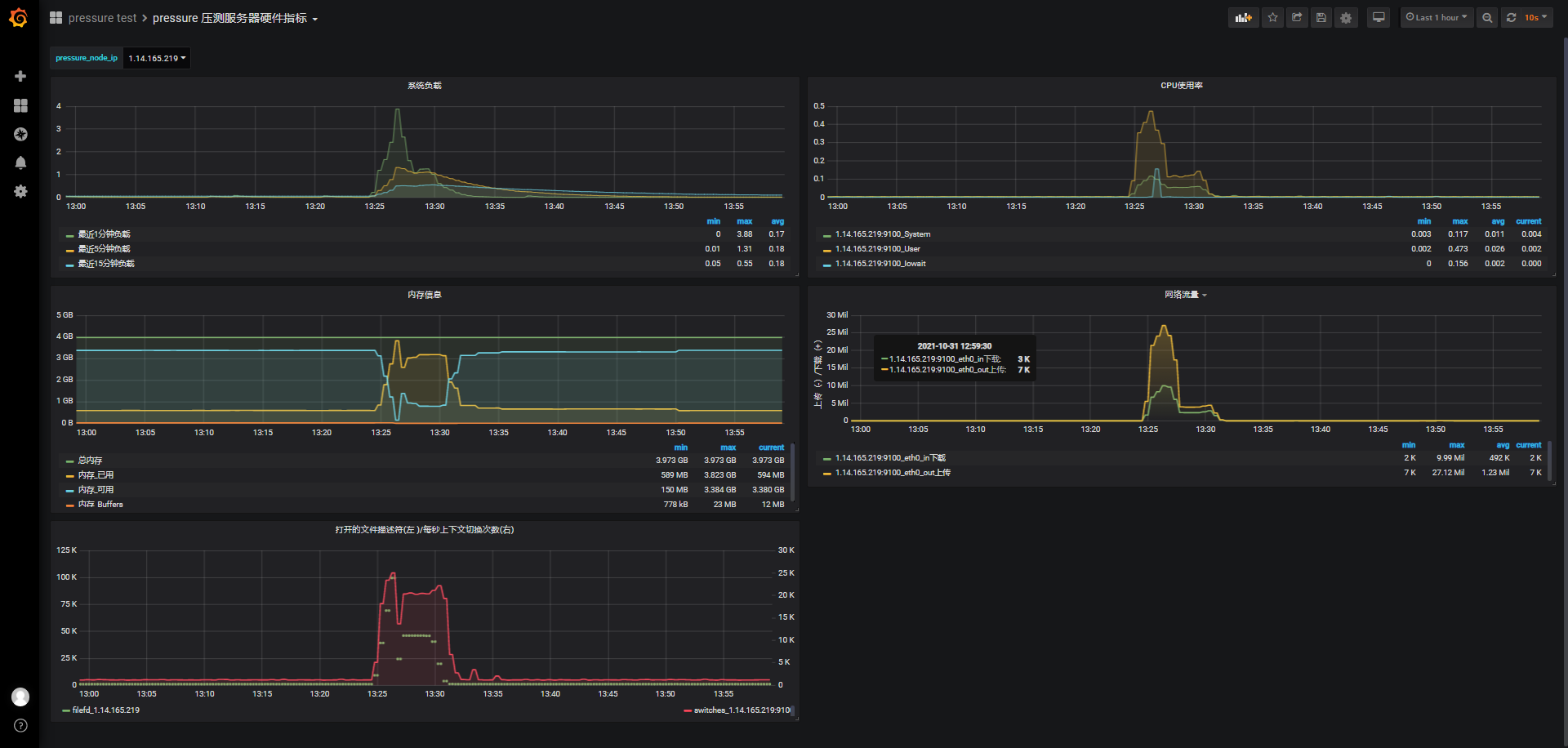
id:wss-connect-rampup-nginx-50000-1031-1325
暂时先调整被测服务器本地端口数
首先,调整ip_local_port_range范围,可提供5w个本地可用端口:
[root@VM-0-14-centos supervisor]# cat /proc/sys/net/ipv4/ip_local_port_range 32768 60999为了测试先调整,如果服务器只有被测服务一个服务的话,可以尝试修改,如果有其他服务且有较多从本地发起对外请求的话,谨慎调整:
echo 10000 60999 > /proc/sys/net/ipv4/ip_local_port_range其次,提高nginx http upstream中ssl_session_cache共享内存为20M。
先看结果,连接数提高了,只有43个失败,也就是有49957个连接成功,但是心跳环节ping and pong失败率很高接近50%,关闭连接更是70%的失败率,可能被测服务被kill了:
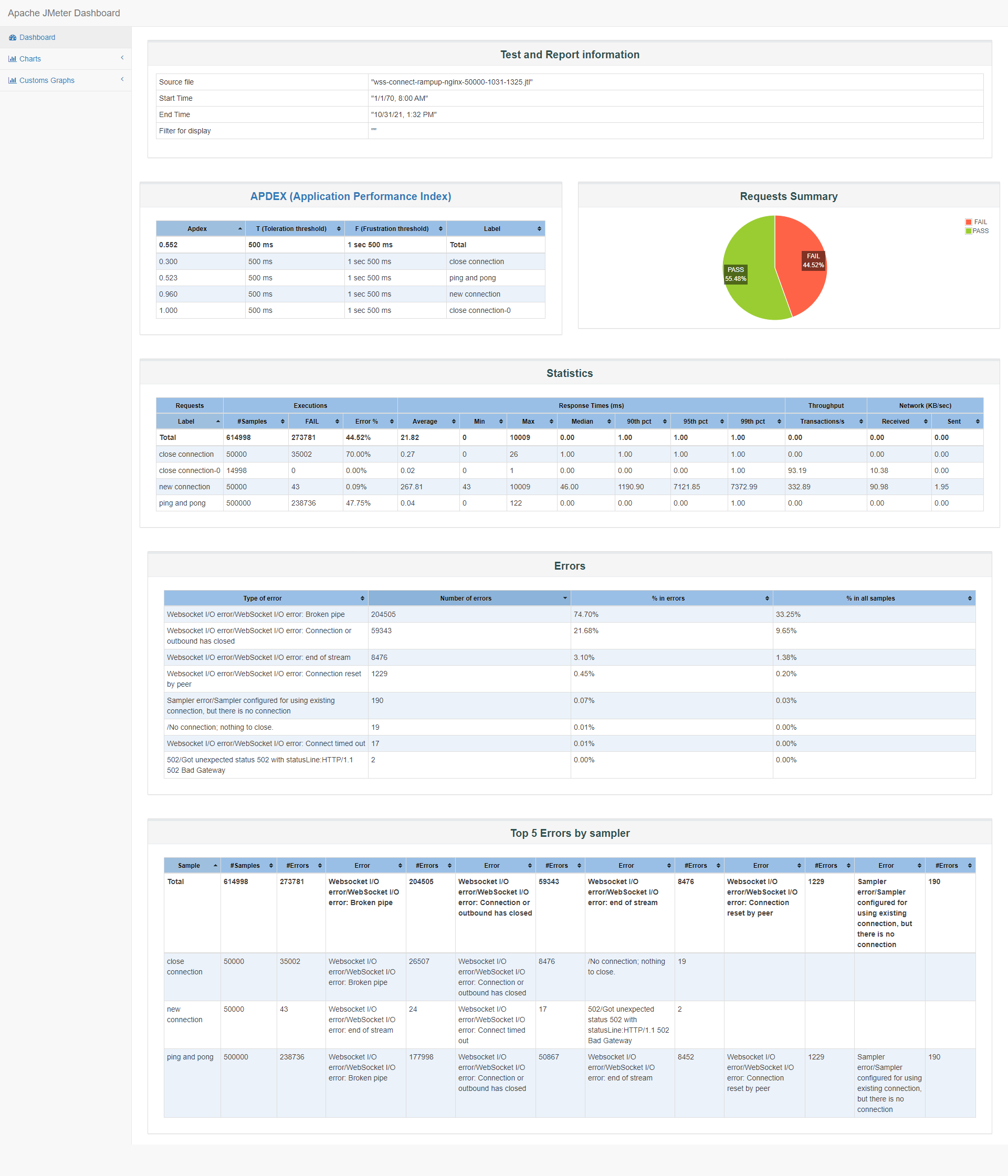
查看系统日志,确实系统kill了被测服务wssrv,虽然系统因为OOM去kill了wssrv,但其实nginx也是很大的一个原因,nginx作为转发代理同时扮演服务端与客户端消耗247237*4KB + 215902*4KB,合计1.77G;而wssrv服务这次只消耗了2104508kB ,约2G:
Oct 31 13:27:12 VM-0-14-centos kernel: [ pid ] uid tgid total_vm rss nr_ptes swapents oom_score_adj name Oct 31 13:27:13 VM-0-14-centos kernel: [32173] 0 32173 37383 684 27 0 0 vim Oct 31 13:27:13 VM-0-14-centos kernel: [ 1398] 0 1398 12619 214 20 0 0 nginx Oct 31 13:27:13 VM-0-14-centos kernel: [ 1399] 1000 1399 247237 222147 481 0 0 nginx Oct 31 13:27:13 VM-0-14-centos kernel: [ 1400] 1000 1400 215902 193186 420 0 0 nginx Oct 31 13:27:13 VM-0-14-centos kernel: [ 1597] 0 1597 526127 351061 726 0 0 wssrv Oct 31 13:27:13 VM-0-14-centos kernel: Out of memory: Kill process 1597 (wssrv) score 351 or sacrifice child Oct 31 13:27:14 VM-0-14-centos kernel: Killed process 1597 (wssrv), UID 0, total-vm:2104508kB, anon-rss:1404244kB, file-rss:0kB, shmem-rss:0kB因为系统OOM,所以出现了心跳和关闭连接的大量错误。
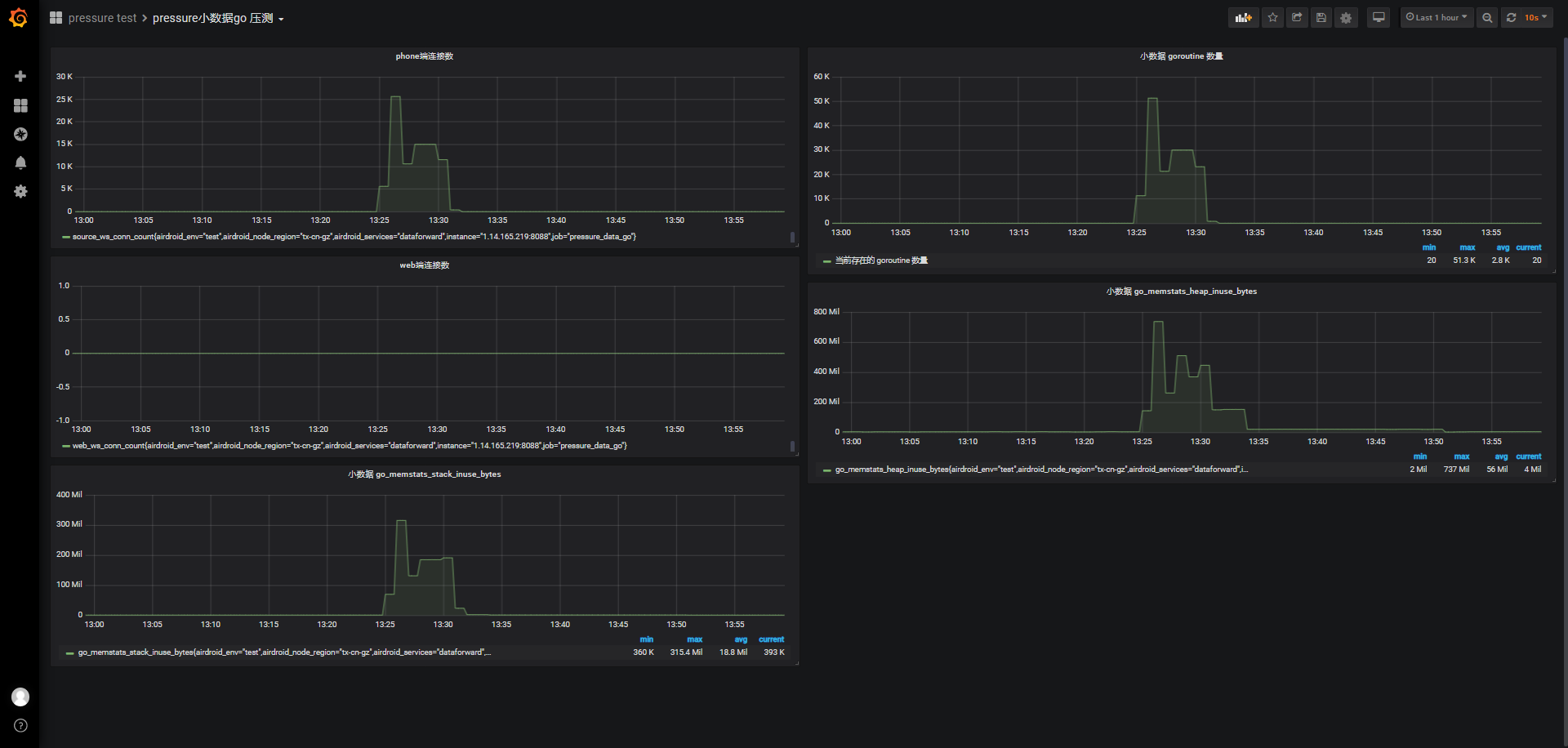
-
4w/150s
id:wss-connect-rampup-nginx-40000
和5w连接的结果类似,但心跳失败率低到60%:
Oct 31 14:18:13 VM-0-14-centos kernel: [ pid ] uid tgid total_vm rss nr_ptes swapents oom_score_adj name Oct 31 14:18:14 VM-0-14-centos kernel: [23004] 0 23004 526143 350872 725 0 0 wssrv Oct 31 14:18:14 VM-0-14-centos kernel: [23057] 0 23057 12619 213 19 0 0 nginx Oct 31 14:18:14 VM-0-14-centos kernel: [23058] 1000 23058 207517 186753 402 0 0 nginx Oct 31 14:18:14 VM-0-14-centos kernel: [23059] 1000 23059 250525 227565 486 0 0 nginx Oct 31 14:18:14 VM-0-14-centos kernel: Out of memory: Kill process 23004 (wssrv) score 351 or sacrifice child Oct 31 14:18:14 VM-0-14-centos kernel: Killed process 23004 (wssrv), UID 0, total-vm:2104572kB, anon-rss:1403488kB, file-rss:0kB, shmem-rss:0kB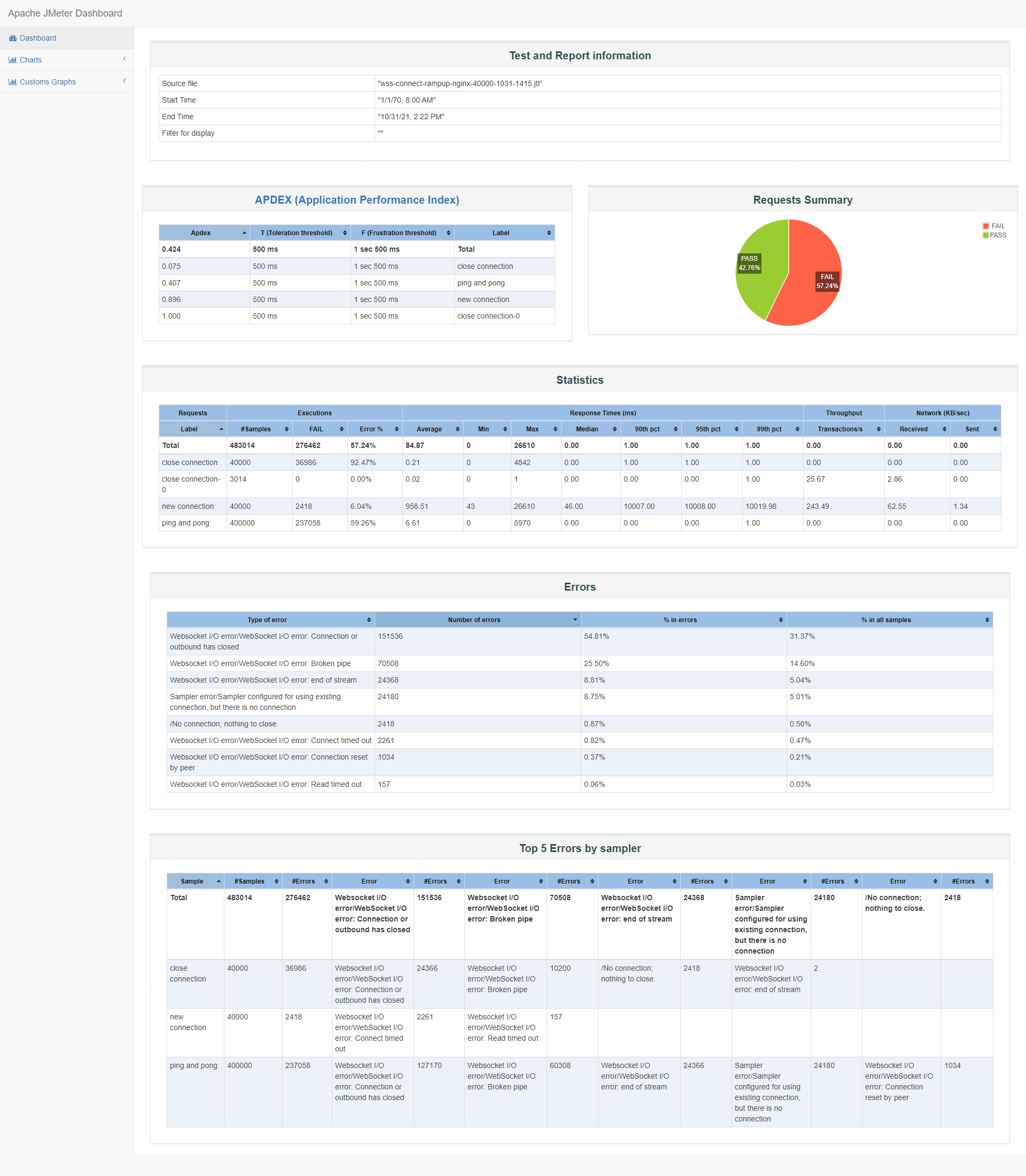
中间服务重启了,所以在14:17左右出现了监测数据空白:
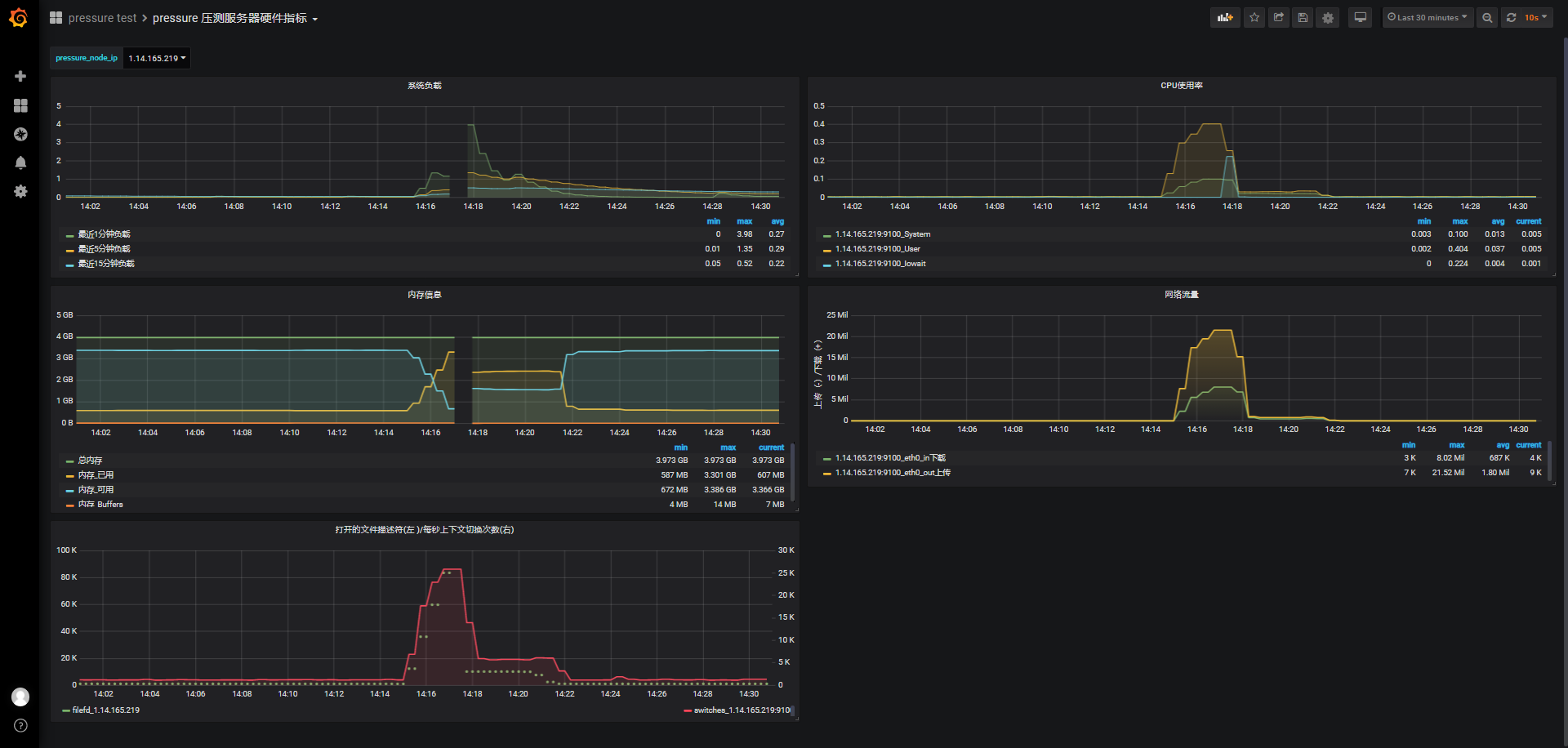

综合之前wss直连测试结果及nginx可能占用内存量,我们觉得2.5w连接是一个比较接近最大的连接数。
-
2.5w/120s
id:wss-connect-rampup-nginx-25000-1031-1434
2.5w全部连接成功且保持心跳10次,连接、心跳、关闭连接满意度都是1.0,这里不贴,可参考下一组3w测试。
连接前系统可使用内存3.39G,保持连接期间内存最低可使用内存672M,共消耗2799M内存,1个连接合计约消耗114K内存(wssrv、nginx),理论还可以支持6000左右连接:
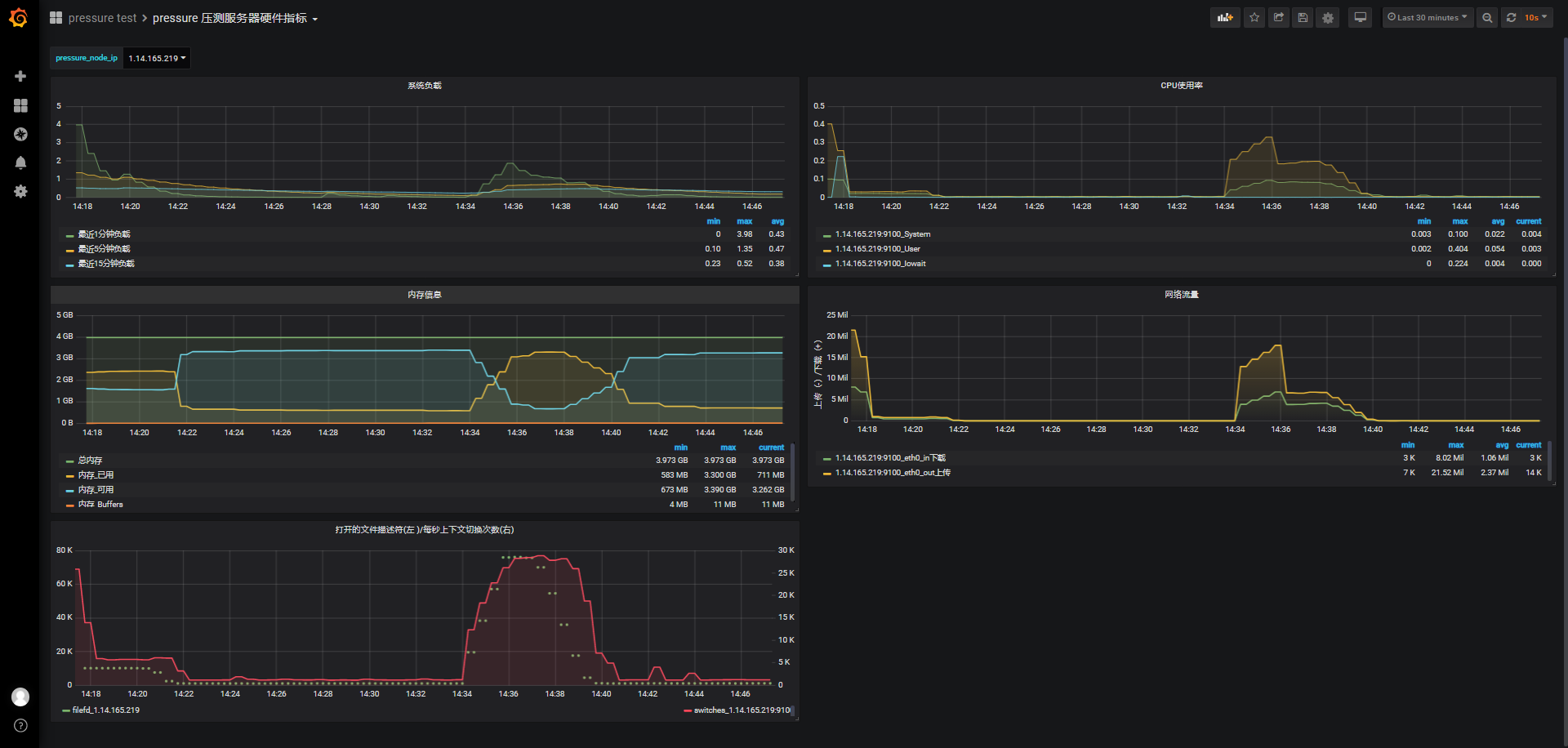
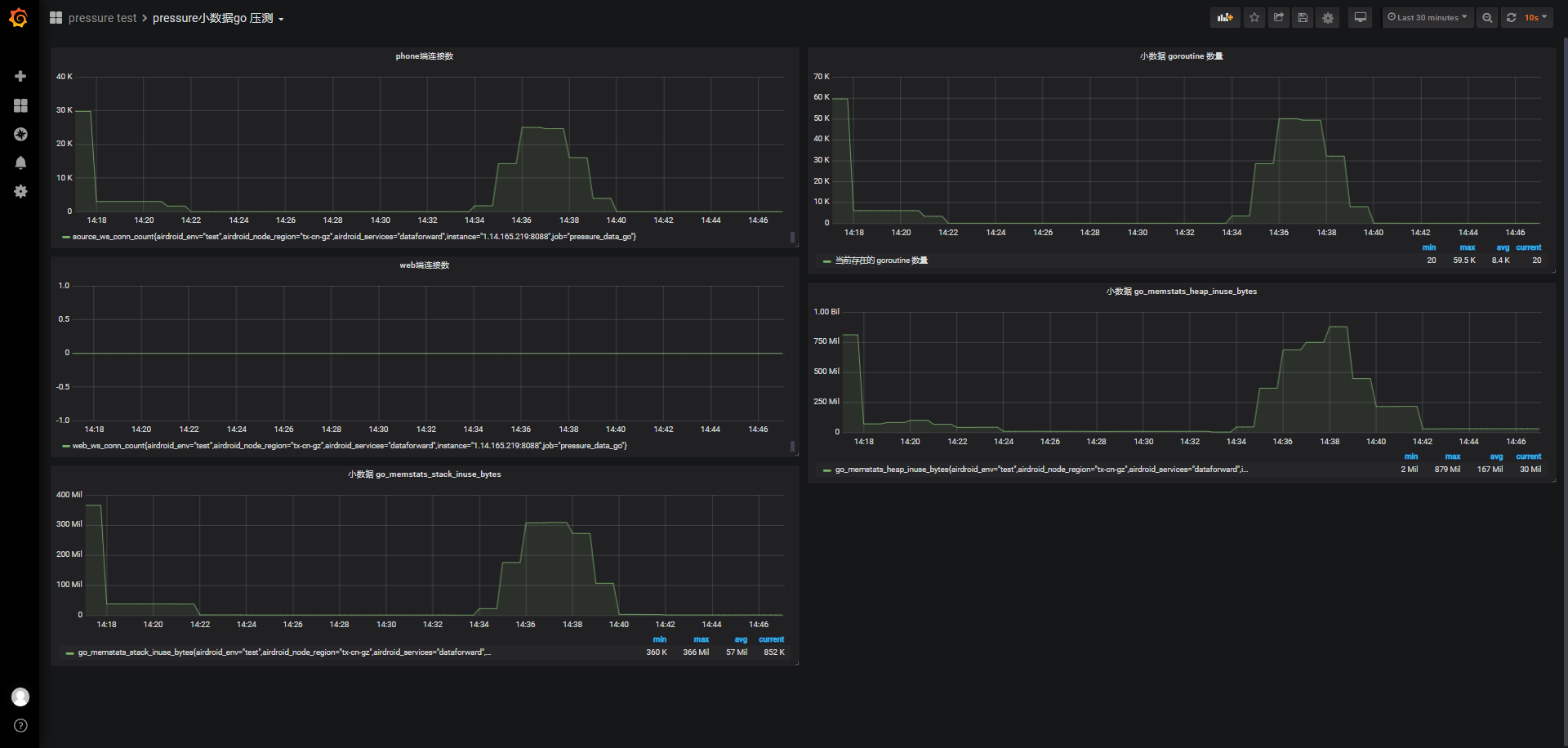
-
3w/120s
id:wss-connect-rampup-nginx-30000-1031-1454
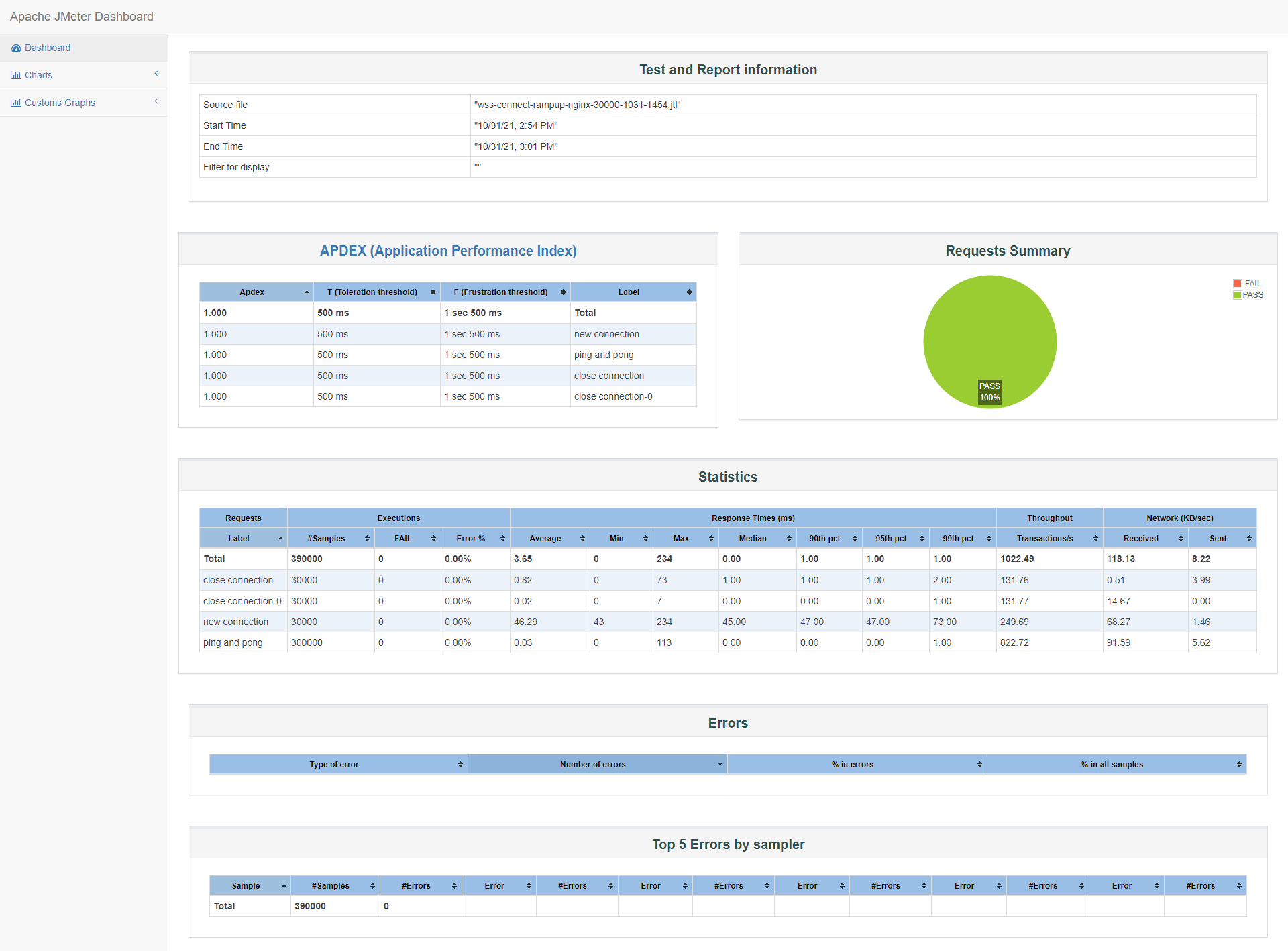
连接前系统可用内存3.382G,保持连接期间最低可使用内存154M,消耗3309M内存:
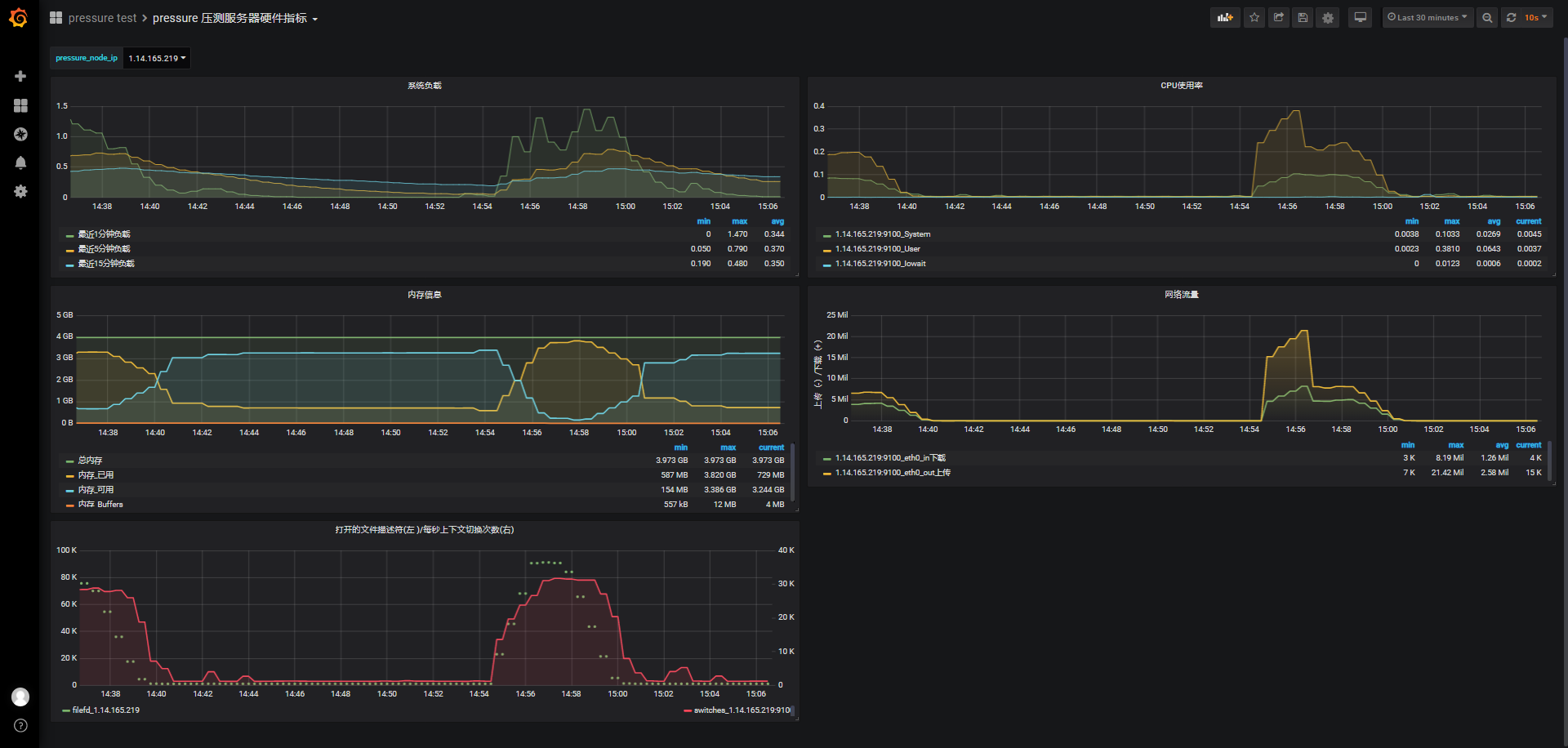
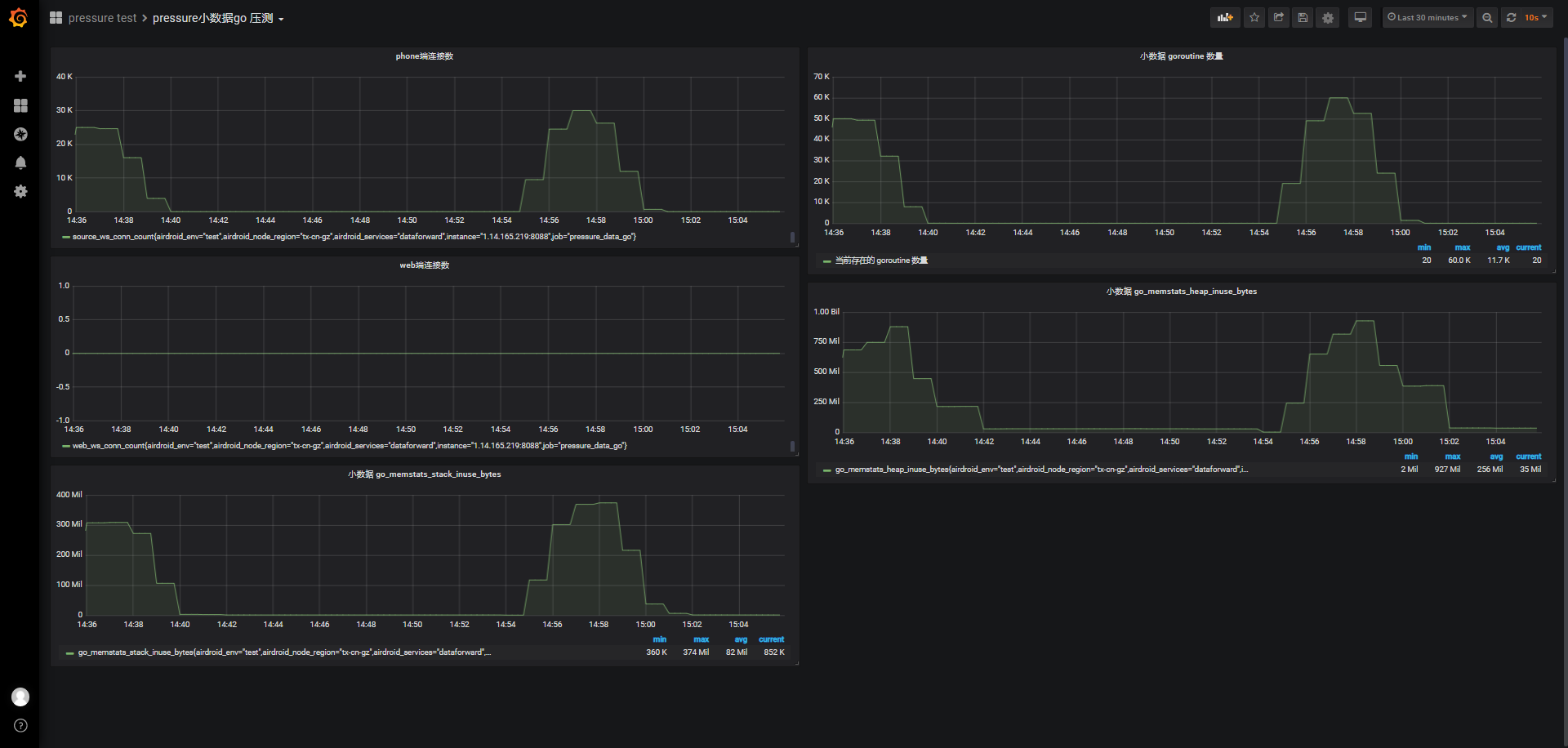
以下是某一次系统top内存使用情况快照,进一步了解nginx确实占用不少内存,本次快照中合计占用31%内存:
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 26003 root 20 0 1965236 1.2g 5484 R 31.3 32.6 0:51.91 wssrv 26053 nginx 20 0 741772 657708 2036 S 4.7 17.0 0:25.66 nginx 26054 nginx 20 0 627052 550524 2060 S 4.0 14.2 0:21.51 nginx 8457 root 20 0 1080460 108252 8548 S 0.7 2.8 178:46.11 YDService 26184 root 20 0 1203544 15096 2004 S 0.3 0.4 55:06.99 barad_agent 759 root 20 0 116012 14596 3852 S 0.0 0.4 5:38.23 node_exporter
小结:
| item | nginx+wss | wss直连 |
|---|---|---|
| 可支持最大wss连接数 | 3w-3.2w | 5w - 5.2w |
| 最大负载 | 1.4 | 3.5 |
| 最高CPU使用率 | 0.38(user),0.1(system) | 0.66(user),0.1(system) |
| 最大使用内存 | 3309M,剩余154M可用 | 3.449G,但OOM了 |
| 每个连接消耗内存 | 110K-120K | 65K-70K |
从表格上可以清楚了解nginx+wss可支持连接数近2w(40%),单位连接消耗内存增加了,主要原因在于nginx服务与被测服务在同一台机器,nginx也占用了30%左右的内存。
注:阶梯连接,负载和cpu使用率仅供了解,不太具备参考意义。
模拟web端控制phone端
这个场景,不做并发,而阶梯连接压测,目的了解web、phone端同时保持连接且交互控制时的最大可连接数。
场景:
30秒(最大150秒)内阶梯性连接所有web端和phone端,维持心跳发送h,客户端心跳时间随机10到30s,维持60次;
web端会在60次心跳中40%的概率发送"let us get together….${__time()}“的消息,也就是每个web端大概会发送24次消息给phone端;
phone端在60次心跳中30%的概率发送"have a nice day….${__time()}“的消息,也就是每个web端大概会发送18次消息给web端;
在60次心跳之后,随机1到10秒关闭对应连接。
web端发送消息给phone端日志确认如下:
[Info] [E:/src/wssrv/phone_web_pair.go 464] [2021-10-31 15:45:27] [id: (a54475a427bf7cf99ae1a65374c213be) send to phone=>let us get together....1635666327948]
[Info] [E:/src/wssrv/phone_web_pair.go 464] [2021-10-31 15:45:27] [id: (5905c5a3208909ab7d2b504ffb620370) send to phone=>let us get together....1635666327947]
phone端发给web端的消息"have a nice day…",之前忘了补充日志,暂时看不到日志。
尝试了这些连接数:
-
3w/120s
id:wss-web-phone-nginx-30000-1031-1536
15000个web端+15000个phone端
根据前面nginx+wss阶梯连接的压测结果,我们尝试15000个web端+15000个phone端。
15000个web端+15000个phone端各自成功连接,使用内存会比单端phone端3w并发使用内存低些。连接前可用内存3.387G,保持60次心跳期间最低可用内存846M(偏差10M),消耗2621M,一对phone端和web端同时连接消耗179K左右内存,结合之前我们认为一个phone端连接消耗114K左右(当然包含nginx消耗内存),单个web连接消耗65K左右,与之前ws、wss直连下的测试结果单端连接消耗内存在68K左右接近。
系统负载最高时1.35,在保持心跳期间也一直维持在1左右,但最近15分钟的负载还是逐步上升的,最后大概稳定在0.6。
cpu使用率也不高,除了连接期间的突然上涨,保持连接期间,实在是没有太多计算,也维持在0.18上下波动,不超过0.2。
从goroutine数量的统计看,保持连接期间,总共开启45K个goroutine,结合之前单端phone端(kid)一个连接会有2个goroutine,从代码web端的连接除了主线程外没有额外的goroutine,所以15000个web端+15000个phone端刚好是45K个goroutine。
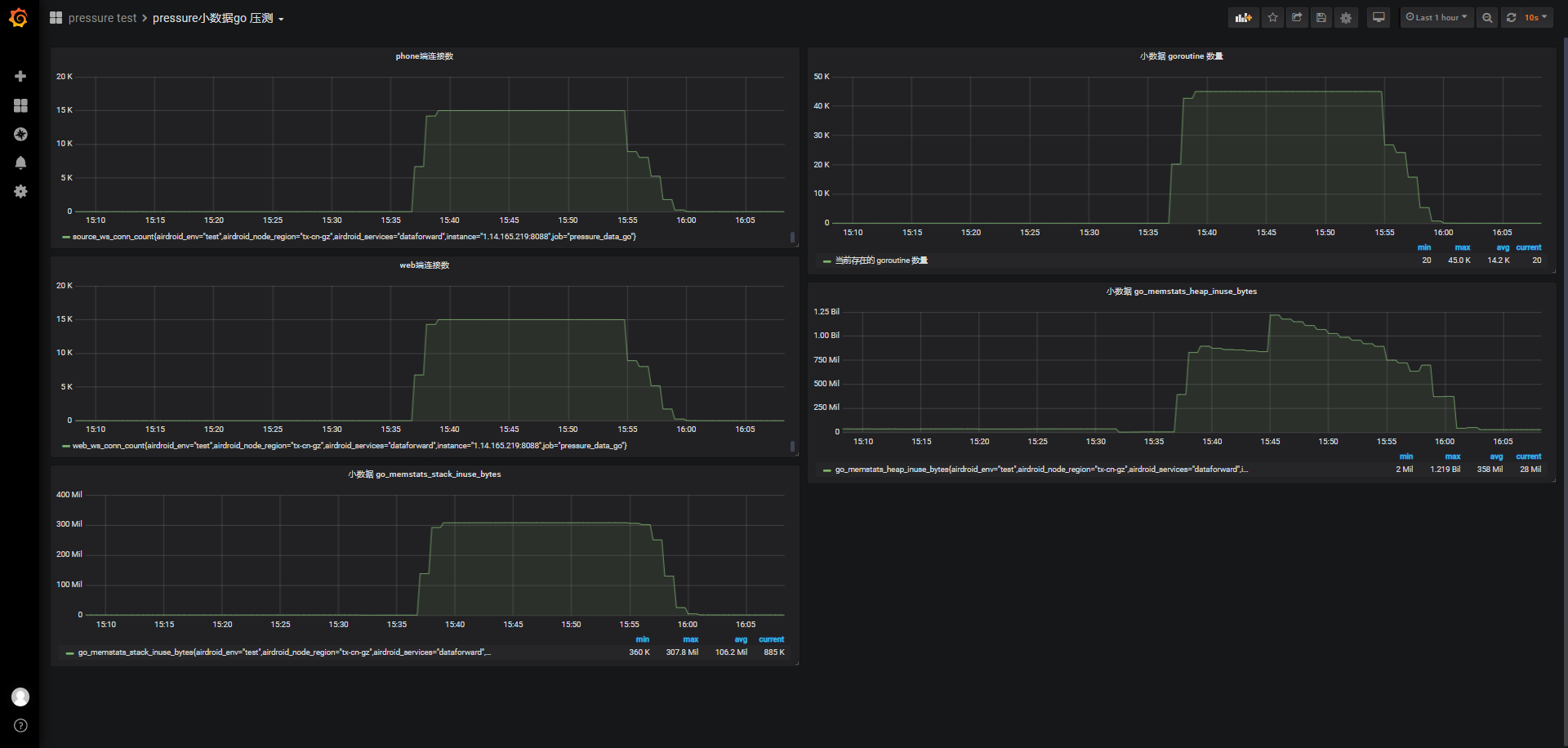
-
3.78w/150s
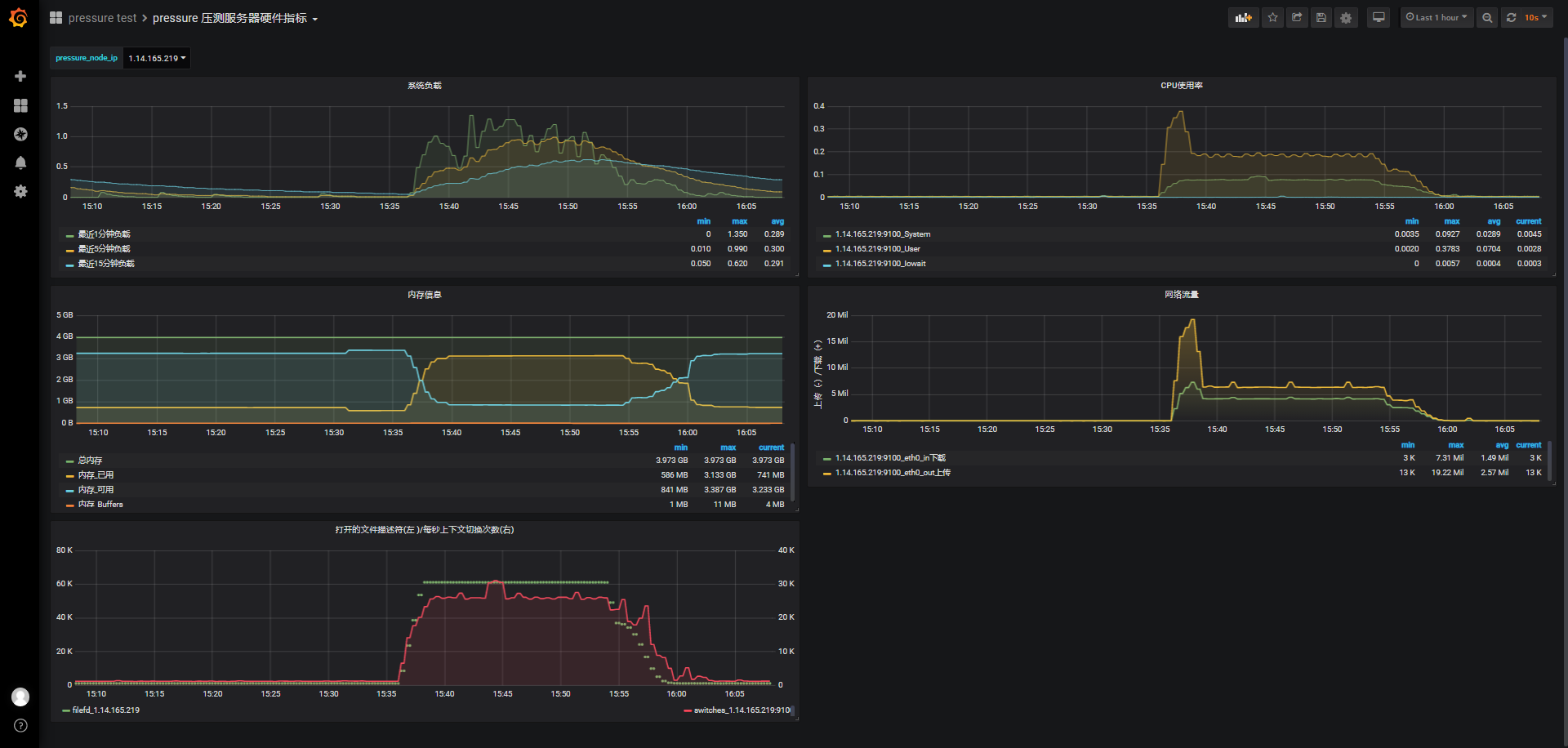
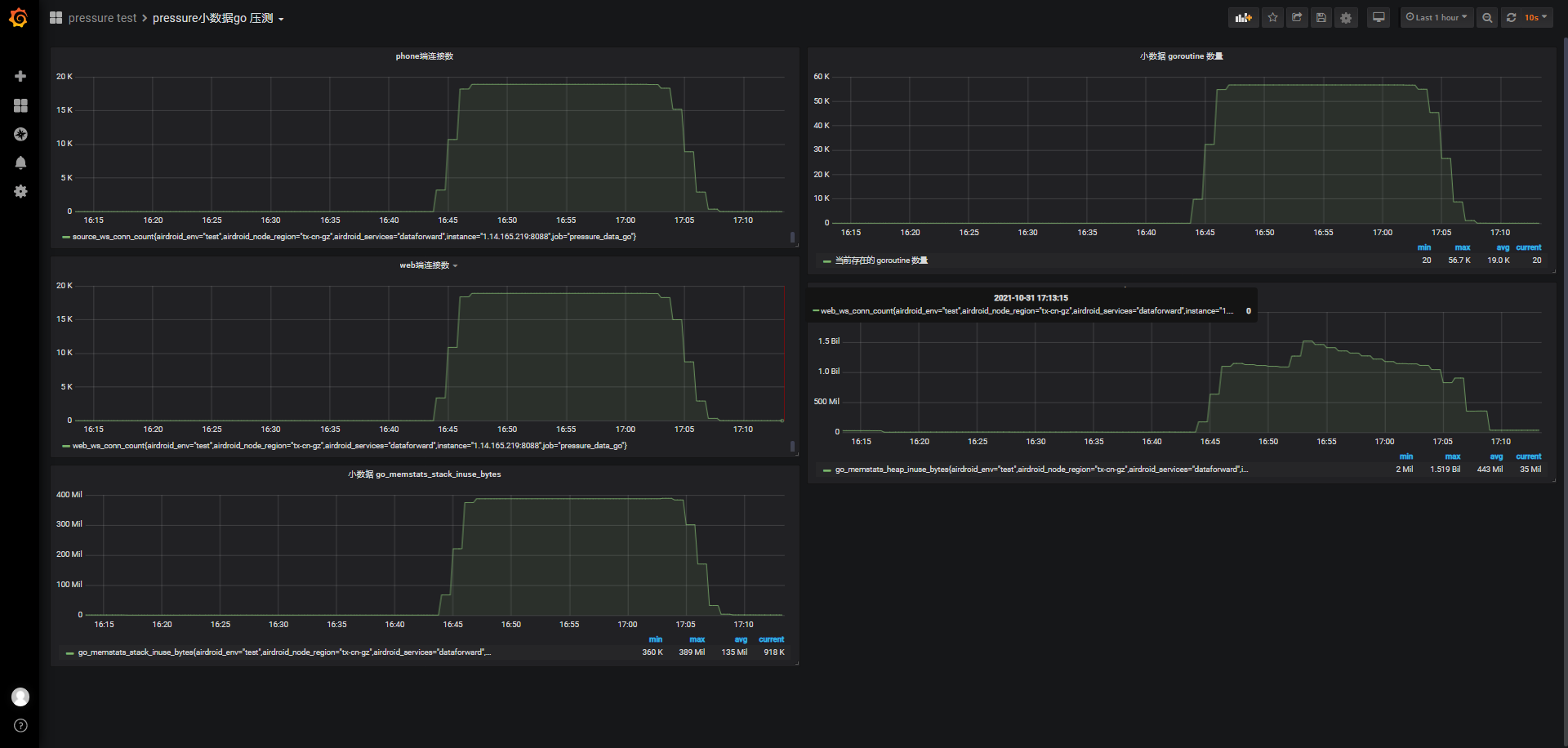
id:wss-web-phone-nginx-37800-1031-1643
18900个web端+18900个phone端
负载最高2.5,维持心跳期间在1.5上下波动,最近15分钟负载逐渐上升,稳定在1.0附近;用户态cpu使用率最高0.4,之后维持在0.2,内核cpu使用率依然在0.09左右;连接前可使用内存3.409G,维持连接期间最低可使用内存179M,消耗3311M内存。

这里jmeter报告概览主要是确认连接、心跳、消息发送、连接关闭成功情况,其他仅供参考:
由于我们需要比对的是wss直连与nginx转发wss,不再进一步压测。根据前面推算,剩余内存179M大约还能支持1000+对,所以大概可支持最大模拟连接数在3.78w-4w之间。
小结:
2核4G服务器目前可以支持1.89w个web端与1.89w个phone端同时连接wss,并维持至少60次心跳(为了缩短压测时间,每次心跳随机在10~30秒之间,正式心跳时长是2分钟/5分钟),web端随机发送24次消息给phone端,phone端随机发送18次消息给web端。
| item | nginx+wss | wss直连 |
|---|---|---|
| phone连接数 | 1.89w | 2.5w |
| web连接数 | 1.89w | 2.5w |
| 最大使用内存 | 3311M | 3297M |
| 最高负载 | 0.4 | 0.56 |
| 最高cpu使用率 | 2.5 | 2.6 |
注:非并发,负载和cpu使用率仅供参考
服务端并发主动断开连接
该场景针对服务端由于网络或外界因素,导致客户端异常断开,服务端可能出现并发主动关闭已有连接的情况,我们想去了解并发断开所有连接时服务器的状态,我们考虑通过心跳机制来触发并发断开连接:
场景:
在之前单端并发压测场景基础上,我们并发2500连接,成功连接后,发送消息tsing(非心跳消息h)到服务端30次,每次10~30秒,大概持续10分钟左右,由于phone端(kid)心跳机制在web端不在线情况下,默认服务端检查心跳时长为5分钟+10秒,所以在5分钟后,第一次检查心跳时,服务端给phone端发送心跳唤起消息,并设定1分钟后关闭连接,如果phone端不响应心跳的话,当然在这个场景中phone端不会响应心跳,所以在1分钟后服务端会主动关闭连接。
根据前面的测试结果,nginx+wss下客户端并发目前能达到全部连接成功的最大连接数在2500左右,如果以2500作为服务端并发主动关闭连接数,这样的并发量不大,难以模拟更多并发数量的服务端主动关闭连接。
但也先做一组2500的服务端并发主动关闭连接,观察引入nginx后,服务端主动关闭连接是否有大的差异。
在17:31到17:37连接期间(差不多在6分钟),我们观察到被测服务wssrv建立的TCP连接有2556个,也就是至少2500个,当结束时,这2500个TCP连接也都断开。
.
.
tcp6 0 0 127.0.0.1:8088 127.0.0.1:16774 ESTABLISHED 17376/dataforwardsr
tcp6 0 0 127.0.0.1:8088 127.0.0.1:16014 ESTABLISHED 17376/dataforwardsr
[root@VM-0-14-centos nginx]# netstat -lanpt |grep data |wc -l
2556
[root@VM-0-14-centos nginx]# netstat -lanpt |grep data |wc -l
56
[root@VM-0-14-centos nginx]# date
Sun Oct 31 17:37:42 CST 2021
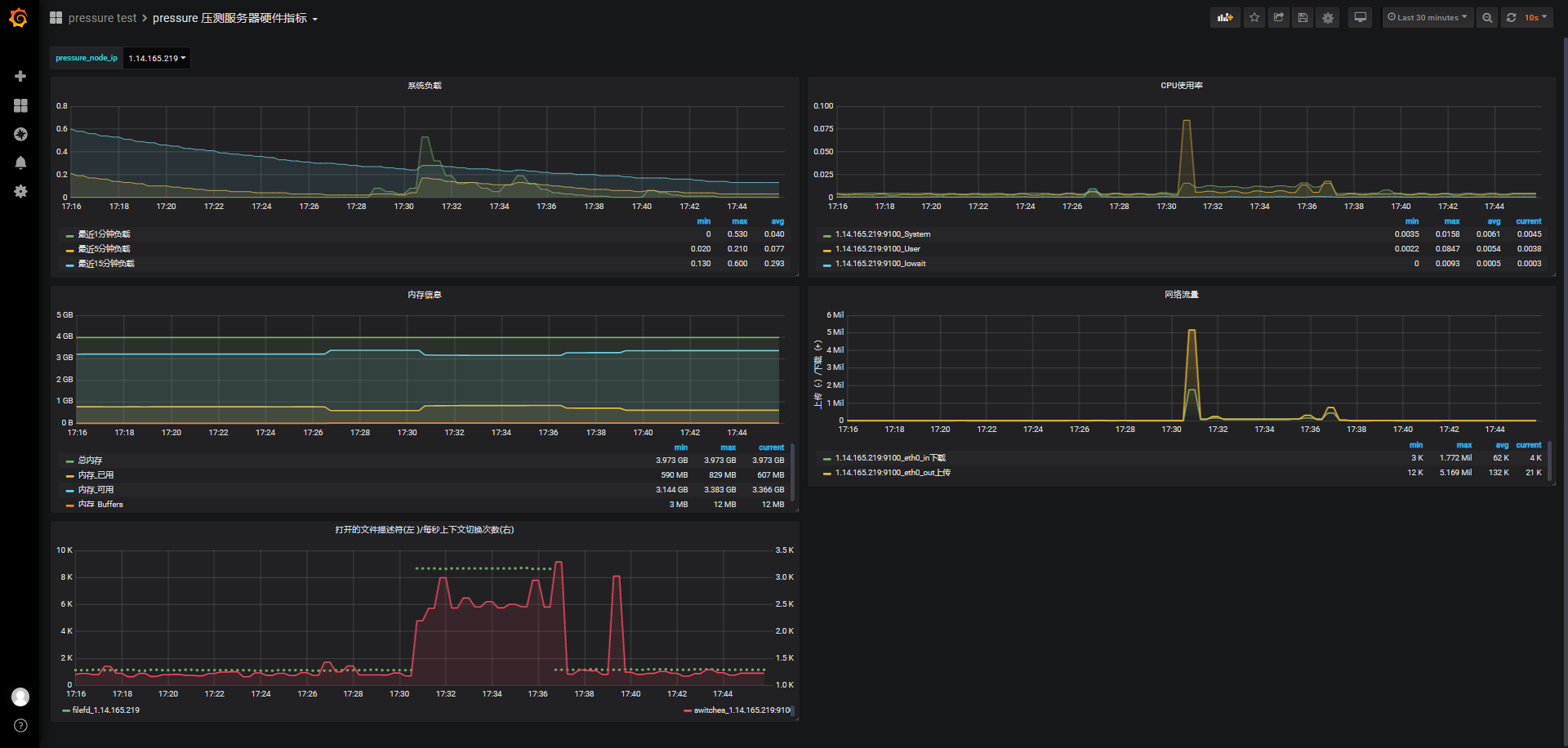
nginx的内存也回落到空连接时的0.8%占比(启动时0.7%)
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
17376 root 20 0 786440 112844 5656 S 0.0 2.9 0:13.92 wssrv
8457 root 20 0 1080464 109220 8688 S 1.3 2.8 180:49.95 YDService
17353 nginx 20 0 79724 30500 2356 S 0.0 0.8 0:04.00 nginx
17352 nginx 20 0 79724 30240 2096 S 0.0 0.8 0:04.12 nginx
至于并发关闭连接,并不会比并发连接消耗更多资源(不考虑客户端)。
报告中我们看到2500个连接成功,一直在发消息,并没有主动关闭连接,而服务端主动关闭连接后,客户端的send msg请求就出现失败了,所以才有34%左右的失败。
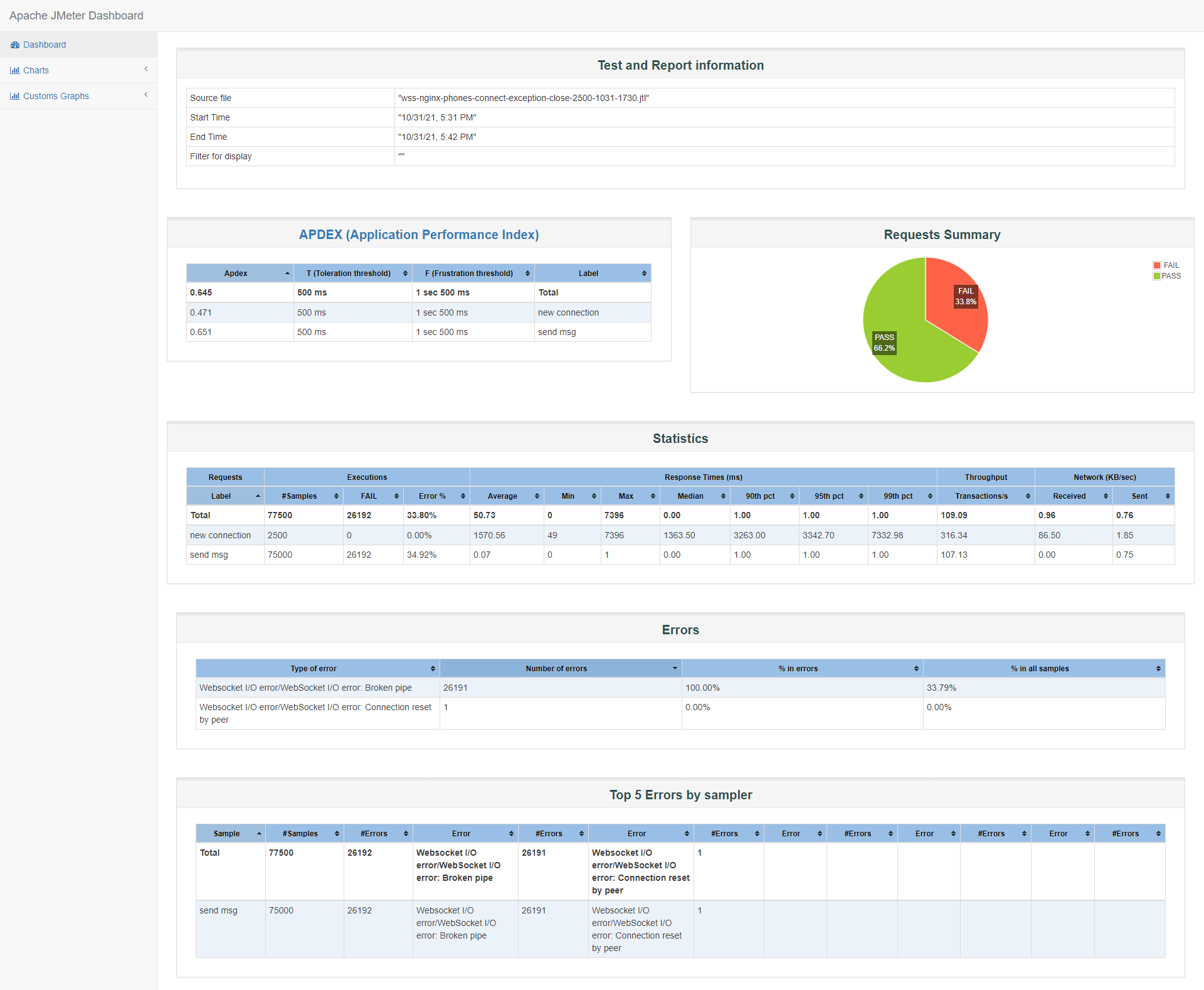
服务器资源消耗很少,主要确认phone端连接数2.5k,并在17:37分断开了所有连接:
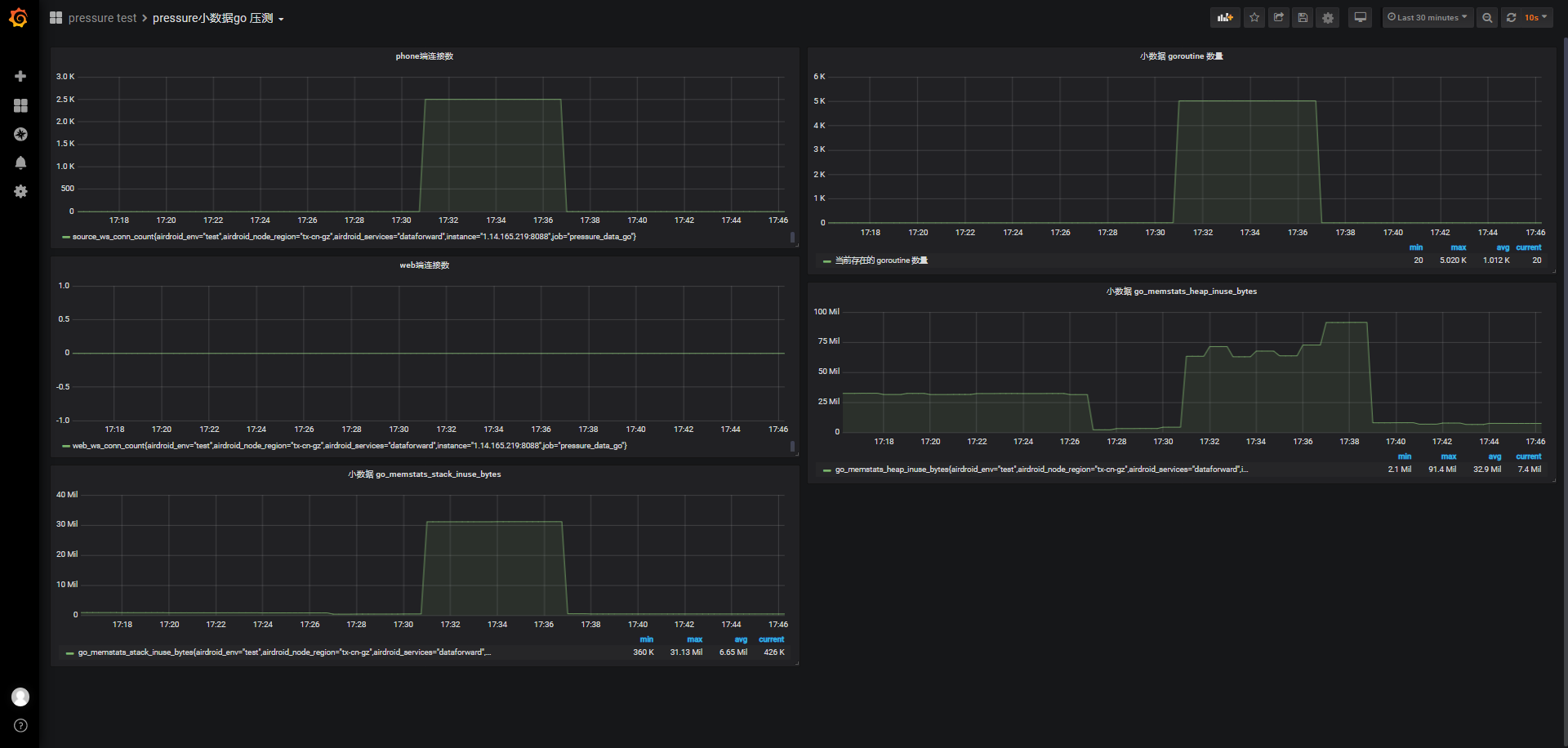
小结:
服务端主动断开,会完整断开client->nginx->wssrv的TCP连接,且内存释放。
这个场景暂时没能做到更大并发下服务端主动同时关闭连接,后续看有机会再考虑。
长时间连接测试
因为本次压测的目的之一就是比对nginx+wss性能、可用性、可靠性、健壮性,也简单模拟测试一个连接在nginx+wss下可维持时长。
在浏览器上的一个phone端连接成功后,每隔120秒发一次心跳h:
wss://test-pressure-data.9ong.com:443/phone?id=ca52b7ebee293a701beb3cad63903380&token=bbede15aa8ff25d917c455a820f290a2&device_type=71&heartbeat=1&instance_id=ca52b7e_e293a70
从前一天下午18点开始一直保活到第二天早上11点,最后重启了服务,被迫中断:
收到消息 17:57:26
{"from":"server","to":"phone","ptype":"event","body":{"command":"/forwardsvr/webstatus/off"}}
收到消息 17:57:26
{"from":"server","to":"phone","ptype":"event","body":{"command":"/forwardsvr/heartbeat/?ws=0&t=300&ws_type=[]"}}
发送消息 17:57:44
have a nice day
发送消息 17:59:34
h
收到消息 17:59:34
{"from":"server","to":"phone","ptype":"event","body":{"command":"/forwardsvr/heartbeat/?ws=0&t=300&ws_type=[]"}}
.
.
.
发送消息 11:09:34
h
收到消息 11:09:34
{"from":"server","to":"phone","ptype":"event","body":{"command":"/forwardsvr/heartbeat/?ws=0&t=300&ws_type=[]"}}
发送消息 11:11:34
h
收到消息 11:11:34
{"from":"server","to":"phone","ptype":"event","body":{"command":"/forwardsvr/heartbeat/?ws=0&t=300&ws_type=[]"}}
结论
单台被测服务器(wssrv),2核4G内存
| item | nginx+wss | wss直连 |
|---|---|---|
| 内网并发 | 1500(nginx配置优化) | 400 |
| 最大连接数 | 3w-3.2w | 5w-5.2w |
-
nginx+wss可支持最大连接数相对更少了,因为nginx占用了部分内存
-
nginx+wss并发数相对较高,nginx在ssl握手及连接会话cache可以做一定的优化
-
内存决定连接数量
从两种方式的测试来看,最大连接数更依赖于内存,内存的提升可以很明显提升连接数量;
-
优化空间
现有并发有一些优化的空间,比如全局锁,减少锁时长,降低ssl握手延迟,提供会话连接缓存,调整代码数据结构去中心化,后端支持nginx转发+分发给分布式业务服务等,详见(优化章节)[#优化]
优化
从连接和保持连接(发消息)的场景测试来看,连接时最消耗资源,也是服务容量的一大瓶颈。并发受限于公共资源的读写,可以考虑pprof去关注全局锁的使用情况,另外我们还想去优化每个连接占用内存,提高可连接数。
-
提高并发连接
从并发连接测试结果看,服务器资源并不是限制并发量的主要原因,由于存在全局锁(可能性最大),并发并行处理被迫串行,导致并发等待。
-
sync.map
使用分段锁,保证数据一致性问题下,提高并发能力。后来,再次了解sync.map,虽然对于读有较大的提升,但对于写反而效果不佳,也就是适合大量度少量写的场景,而我们并发连接时,特别是第一次设备连接,会有map的写,所以如果要调整,还需要测试比对效果。也有人提出想法:对一个大map进行hash,其内部是n个小map,根据key来来hash确定在具体的那个小map中,这样加锁的粒度就变成1/n了。 网上找了下,真有大佬实现了:concurrent-map/README-zh.md at master · orcaman/concurrent-map · GitHub
-
去中心化
依然是通过分而治之指导,比如我们之前已经有的地区load balance,后续可以补充后端LB,在地区的基础上在nginx层再加一层LB,当然调整会涉及到业务代码逻辑,比如phone端和web端需要在同一个治区,统计逻辑等业务调整。
注:治区,可以理解为数据共享块
-
-
提高连接数
不论是ws、wss、nginx+wss的方式,内存是连接数的最大因子,内存越大,可连接数越多,除了wssrv外,nginx服务的内存使用情况也需要考虑:
-
放开本地ip_local_port_range范围
一个连接由4个部分组成,source ip、source port、destination ip、destination port,所以方案两个方向,增多source port与增多destination ip。
如果nginx服务与被测服务wssrv在同一台机器时,可以通过放开ip_local_port_range提高连接数。需要运维评估。
增多source port,提高ip_local_port_range数量
比如
echo 15000 64000 > /proc/sys/net/ipv4/ip_local_port_range -
nginx不仅仅是代理,更是LB
nginx,不仅仅提供转发,后续可以的话,wssrv与nginx服务分离,nginx承担起后端LB的角色,做到1个nginx分发到n个wssrv,提高单台wssrv的连接数,从而提高总的连接数。
增多destination ip,实现后端upstream:
upstream data{ server 127.0.0.1:8088 fail_timeout=0; server 172.16.0.2:8088 fail_timeout=0; server 172.16.0.3:8088 fail_timeout=0; } -
优化wssrv内存使用
通过pprof去了解锁优化内存使用
-
nginx优化
仅供参考,需要运维研究评估确认。
TLS配置优化
TLS设置优化,目的减少延迟。
-
开启http2,比起http1.1快了66%
listen 443 ssl http2;
-
调整Cipher优先级
ssl_prefer_server_ciphers on;
-
启用 OCSP Stapling
用户连接业务服务器的时候,有时候需要去验证证书,我们不想证书服务器并不通畅,可以省略
要使 OCSP stapling 起作用,应知道服务器证书颁发者的证书。如果 ssl_certificate 文件不包含中级证书,则服务器证书颁发者的证书应存在于 ssl_trusted_certificate 文件中。
ssl_stapling on; ssl_stapling_verify on; ssl_trusted_certificate /path/to/full_chain.pem;
-
调整 ssl_buffer_size
官方: 缓冲区默认大小为 16k,对应发送大响应时的最小开销。要将首字节时间(TTFB,Time To First Byte)减到最小,设置较小的值可能会有不错的效果,如:ssl_buffer_size 4k;
sslbuffersize 控制在发送数据时的 buffer 大小,默认设置是 16k。这个值越小,则延迟越小,而添加的报头之类会使 overhead 会变大,反之则延迟越大,overhead 越小。
如果服务器是用来传输大文件的,那么可以维持 16k。
Best value for nginx’s ssl_buffer_size option? · Issue #63 · igrigorik/istlsfastyet.com · GitHub
-
启用 SSL Session 缓存
启用 SSL Session 缓存可以大大减少 TLS 的反复验证,减少 TLS 握手的 roundtrip。虽然 session 缓存会占用一定内存,但是用 1M 的内存就可以缓存 4000 个连接,可以说是非常非常划算的。
默认:ssl_session_cache none; 轻度禁止使用会话缓存:nginx 告诉客户端会话可以重用,但实际上并不会将会话参数存储在缓存中。
ssl_session_timeout 指定客户端可以重用会话参数的时间。
比如:共享50M内存,建议使用shared,而不是builtin。shared:所有 worker 进程之间共享的缓存。缓存大小以字节为单位指定,1M可以存储大约 4000 个会话。每个共享缓存都应有一个任意的名称。可以在多个虚拟服务器中使用有相同名称的缓存。
ssl_session_cache shared:SSL:50m; ssl_session_timeout 4h;
upstream配置优化
-
keepalive
在upstream中的keepalive,不是开启或关闭长连接的意思,而是设置nginx worker的空闲连接池的大小。Module ngx_http_upstream_module - keepalive
Activates the cache for connections to upstream servers.
The connections parameter sets the maximum number of idle keepalive connections to upstream servers that are preserved in the cache of each worker process. When this number is exceeded, the least recently used connections are closed.
It should be particularly noted that the keepalive directive does not limit the total number of connections to upstream servers that an nginx worker process can open. The connections parameter should be set to a number small enough to let upstream servers process new incoming connections as well.
其他
FD文件描述符限制worker_rlimit_nofile
worker_connections连接数、worker_processes等
观察nginx.conf配置,运维那边有做过相关的优化
之后可以根据实际情况继续调优
遗留
- 每次压测后,关闭所有连接,被测服务仍然再用150M到270M左右内存,重启被测服务wssrv后,会被释放,暂时没有去深究为什么
- 我们没有尝试一些比较复杂的场景,比如最大并发后,维持一段时间,再并发小部分连接,甚至考虑再关闭部分连接,继续维持心跳等,如果有这方面的目标,也可以考虑去尝试
参考
Apache JMeter - User’s Manual: Remote (Distributed) Testing
Apache JMeter - User’s Manual: Getting Started - CLIMode
Nginx 99: Cannot assign requested address to upstream - Bugbear Thoughts
Nginx: Cannot assign requested address for upstream
Module ngx_http_upstream_module - keepalive
